Importing data examples
The following example schemas demonstrate the various capabilities of Deephaven table schemas.
Example 1 - Logger and Listener elements
This example demonstrates how to combine logger and listener elements in a table schema for streaming data ingestion. This schema includes separate Listener and Logger elements, as well as a combined LoggerListener element, showing different ways to define data ingestion paths. For more details on streaming data and loggers/listeners, see Streaming data overview.
Example 2 - Simplified streaming schema
This example shows a more compact streaming schema where logger and listener configuration is specified directly as attributes on the Table element, rather than as separate nested elements. This approach is simpler when you don't need custom imports, fields, or complex transformations. For more details on streaming data, see Streaming data overview.
Example 3 - Batch data import using the Schema Editor
The previous two examples focused on streaming data ingestion, which uses loggers and listeners to process row-by-row data in real time. This example demonstrates a different workflow: batch data import from CSV files using the Schema Editor UI and Persistent Queries.
The following walkthrough shows the common steps in setting up a schema and import job for a new CSV batch data source.
The example uses U.S. Federal College Scorecard data from www.data.gov. To follow along with this walk-through, please download and unzip the data file from the College Scorecard data download page.
Click the Advanced button at the top of the Deephaven Console and then select Schema Editor.
Note
The Schema Editor menu item is only available if you are a member of the iris-schemamanagers group.
After accepting the defaults, the Schema Editor panel will open:
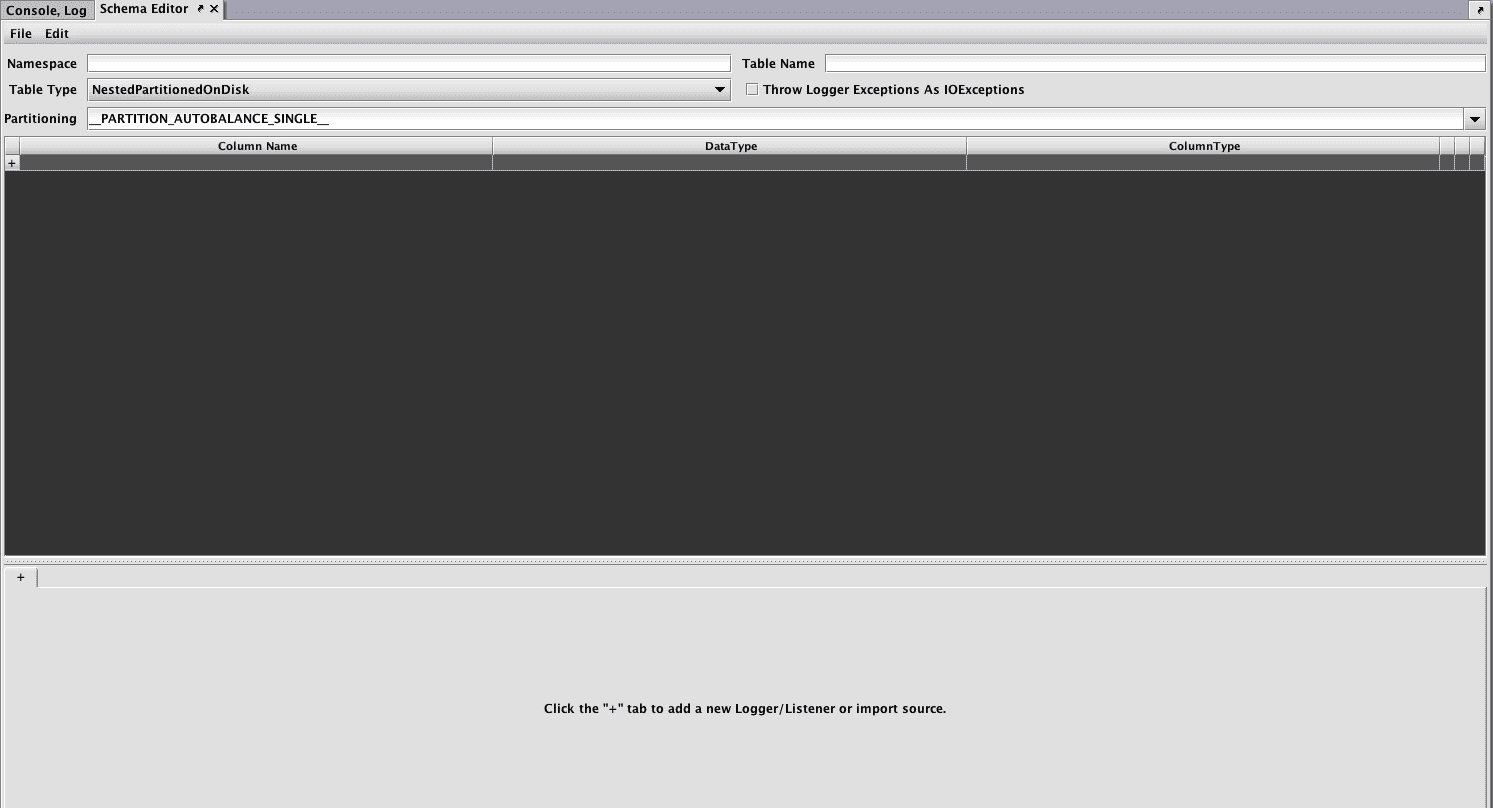
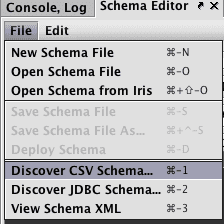
Click the File menu and then select the Discover CSV Schema... option:
When the Discover Schema panel opens, select the ellipsis button (circled below) to the right of the Source File field:
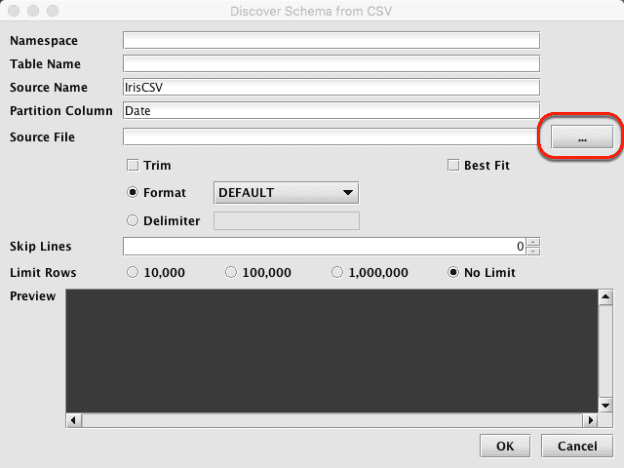
Browse for the CSV file you downloaded earlier:
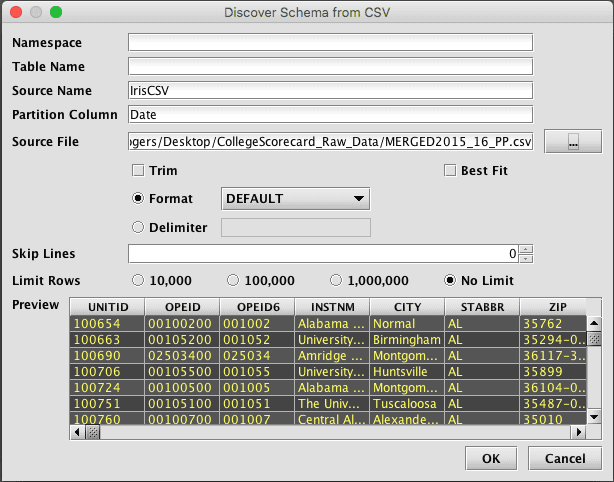
After selecting the file, enter the Table Name and Namespace. (It can also be entered in the main Schema Editor window in the next step.) Format, Skip Lines, and Delimiter should be set here to result in a good preview of the data. For very large files, it may be desirable to limit how many rows are analyzed to infer the data types of the columns. The entire file does not need to be scanned, as long as there is enough representative data in the selected top lines of the file.
Click OK once the preview looks correct. Depending on the size of the file, it may take several seconds or longer to process the file. A progress bar will be shown at the bottom of the window during processing.
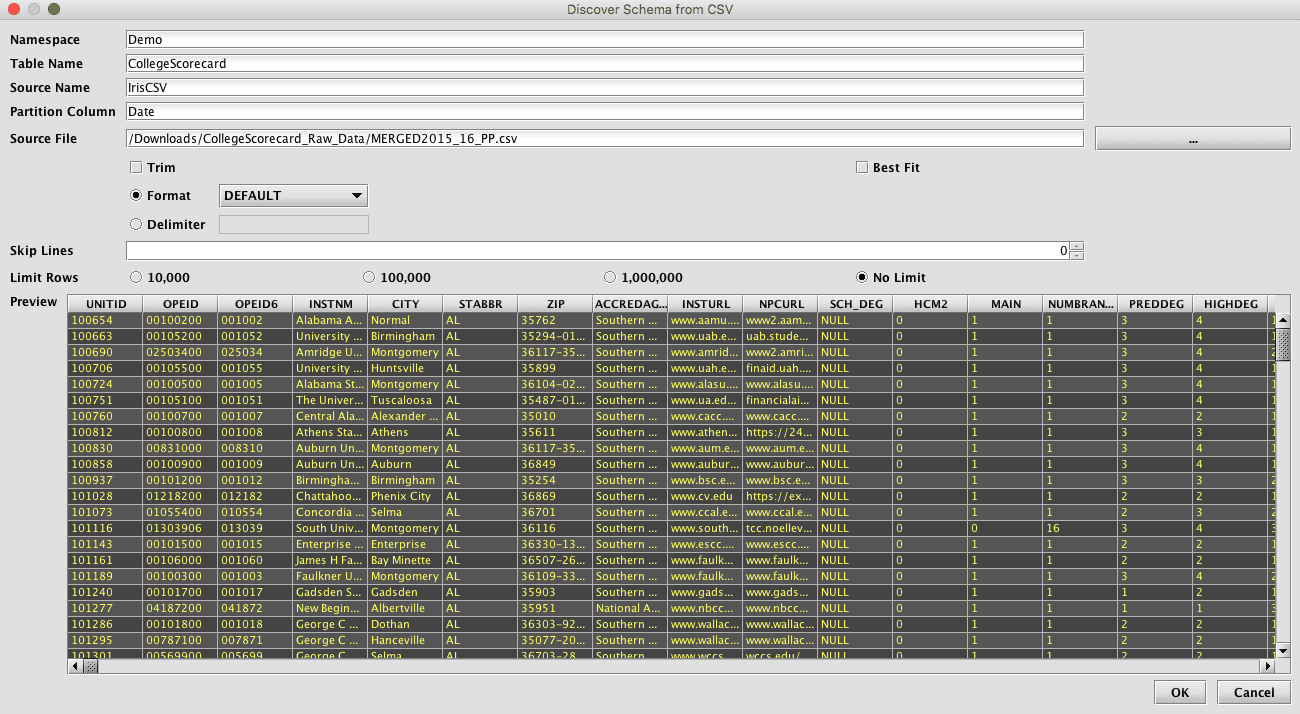
Once processed, the schema details will be shown in the main Schema Editor window. The schema can then be edited from here to change column names, types, order, and import processing, as needed or desired.
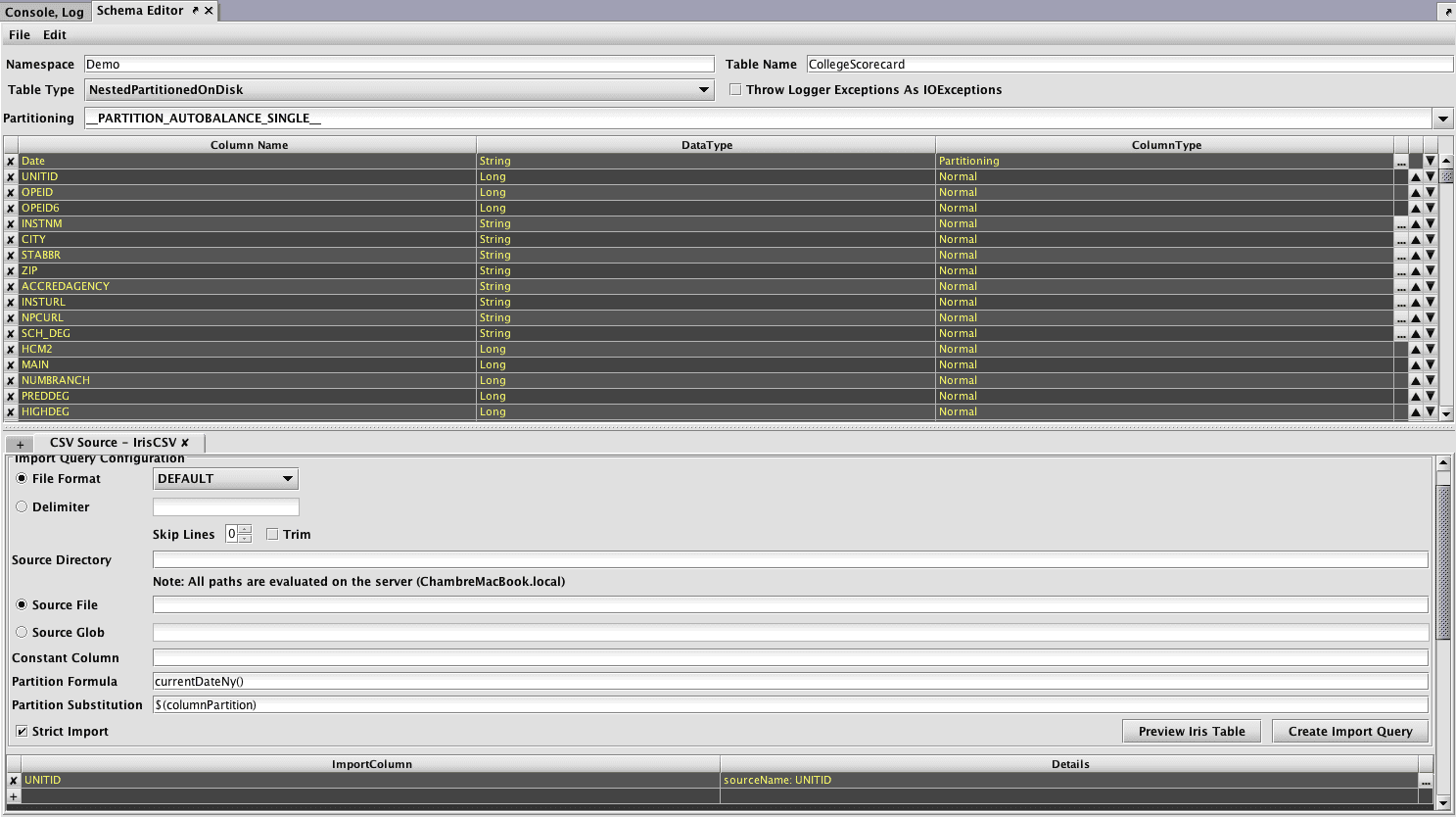
The expected results of an import to Deephaven can then be previewed using the Preview Table button. This action requires that the Source Directory and Source File or Source Glob be completed for a path to source files relative to the query server where the Schema Editor is being run.
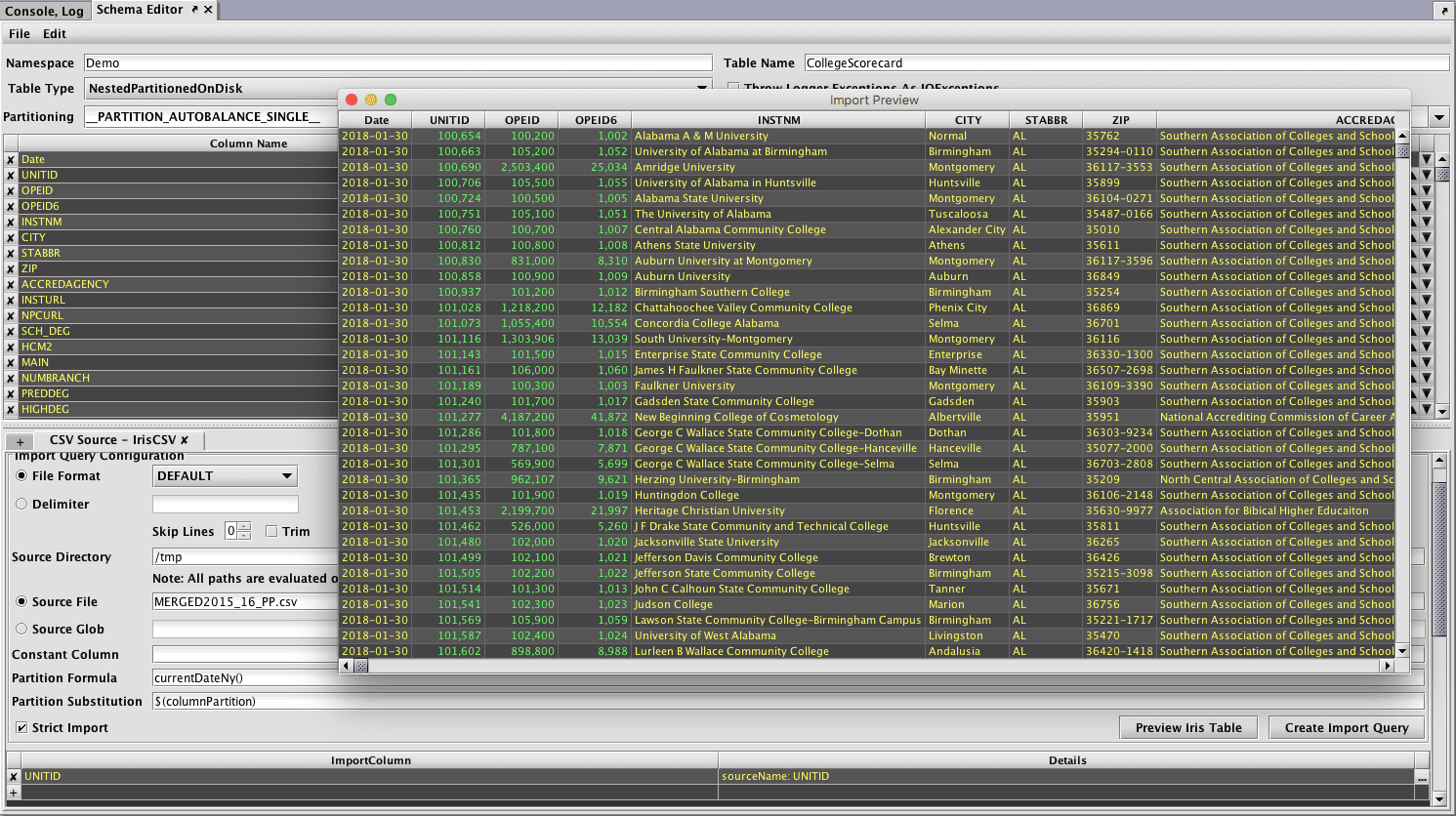
Once the schema and results of a test import are as desired, the schema can be deployed to Deephaven to create a new table definition.
Open the File menu again, and select the Deploy Schema option to deploy the new table to Deephaven. Optionally, the schema file could instead be saved to disk for later use or manual deployment.
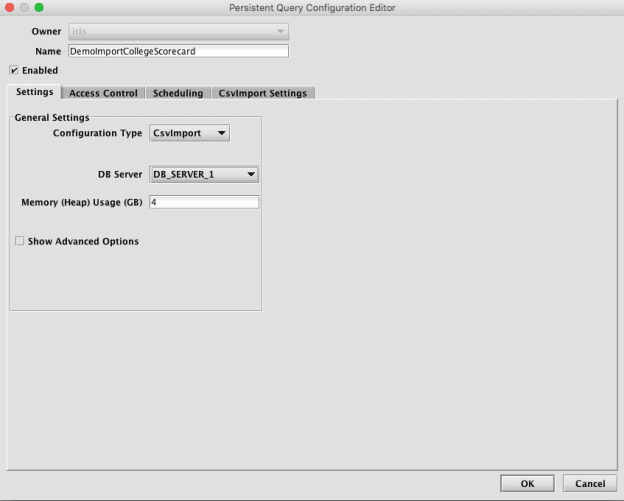
Once the schema is deployed, an Import Query can be created using the Create Import Query button. (You can also use the Create Import Query button to deploy the schema.)
Alternatively, an Import Query can also be created later from the Query Config panel of the Deephaven Classic console. It will be necessary to set basic settings on the Settings tab, at least a timeout on the Scheduling tab, and details of the source file path and name on the CsvImport Settings tab.
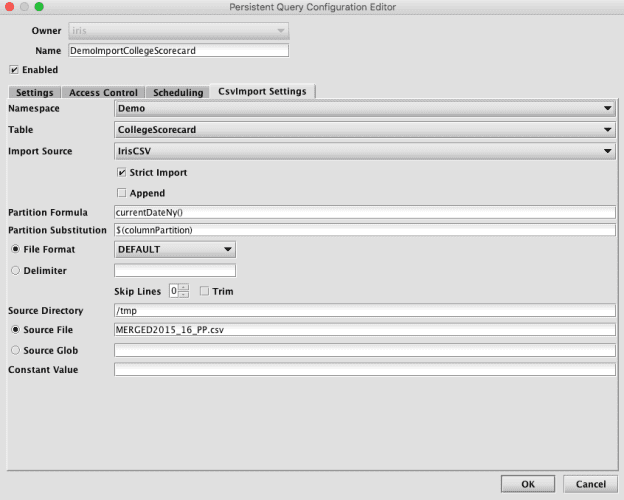
After completing this process, the new Import Query will be displayed alphabetically in the Query Config panel. It can then be run as desired.
