Deephaven database basics
Deephaven is a high-performance time-series database, complemented by a powerful query engine that excels at performing analysis on massive real-time and historical data sets. This page discusses the basic concepts and APIs for interacting with the Deephaven database.
Catalog
The database catalog provides a list of all available tables across all available Deephaven namespaces and can be retrieved in table format as follows:
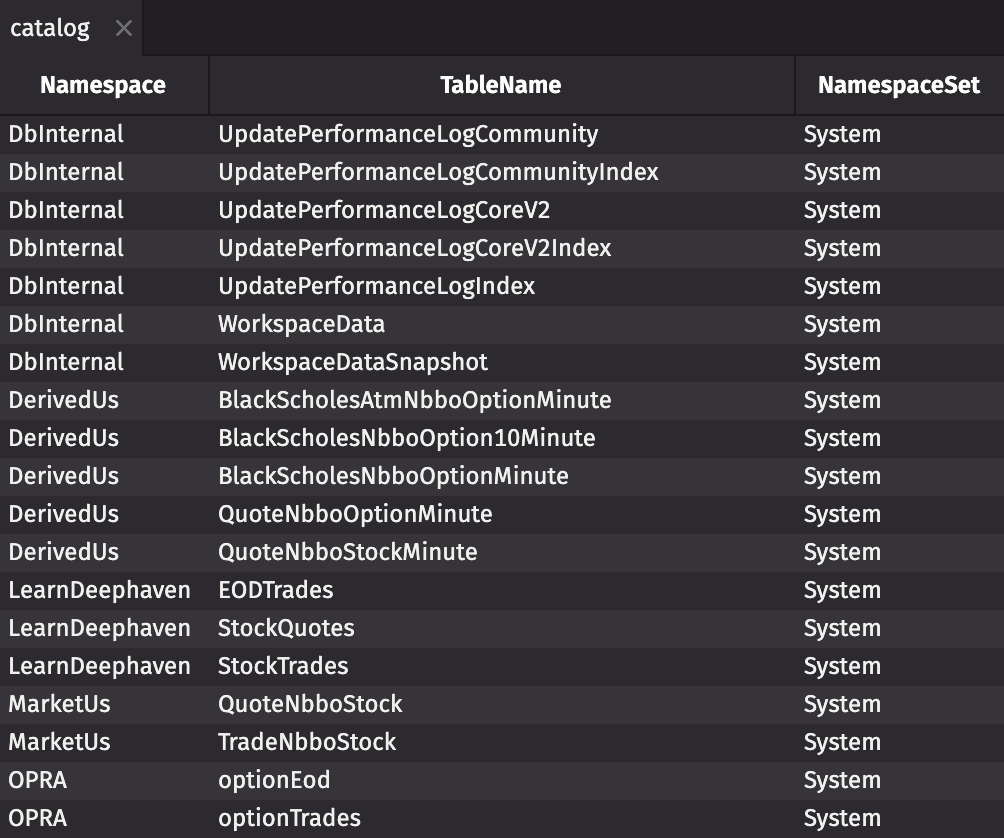
Namespaces
Namespaces in Deephaven are similar to databases in SQL Server/MySQL or tablespaces in Oracle. They group tables together and provide scope for unique table names.

Deephaven Enterprise namespaces are divided into two types:
- System namespaces contain system tables created and managed by administrators.
- User namespaces contain user tables created and managed by users without administrative privileges.
Two example system namespaces:
DbInternal: Contains Deephaven management and monitoring tables.LearnDeephaven: Contains example data tables for learning purposes.
Examples of how to access tables in these namespaces are provided below.
Table names
You can retrieve all table names for a given namespace as follows:

Historical tables
Historical tables are static tables with a fixed number of rows and columns, backed by files on disk. They are immutable and do not change over time.
Historical data for system namespaces is stored under the database root in the Systems directory (usually /db/Systems), and user namespaces in the Users directory (usually /db/Users).
You can query historical tables with the historicalTable method in Groovy or historical_table method in Python. For example:
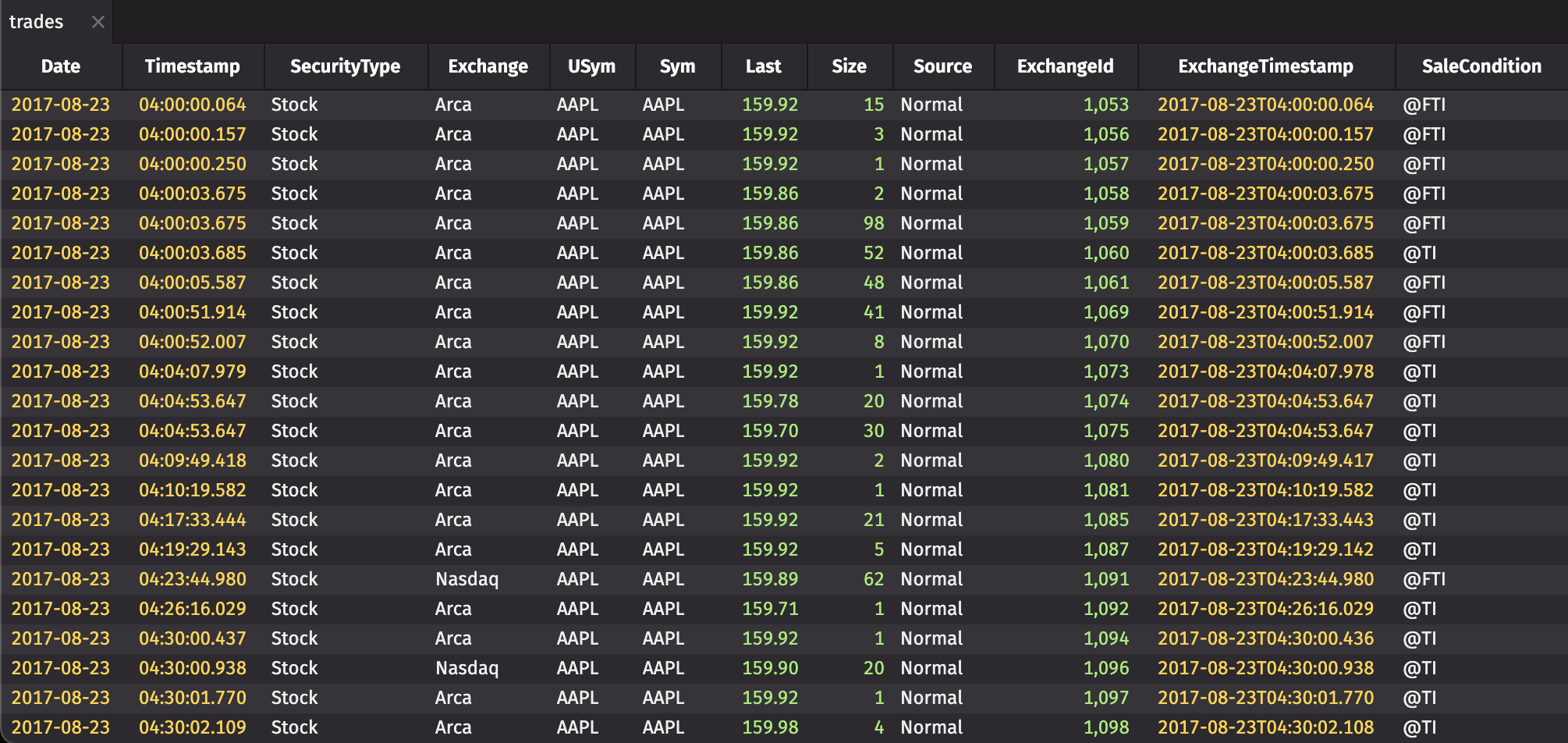
See Historical system tables for more about the layout of historical tables.
Live tables
Live (also known as "real-time" or "intraday") tables can append new rows of data to the table over time, as well as update dynamically and change existing rows as new data arrives.
Intraday data for system namespaces is stored under the database root in the Intraday directory, usually /db/Intraday. Administrators may create an intraday data directory for user namespaces when configuring support for centrally-appended user data, but this is optional.
You can query live tables with the liveTable method in Groovy or live_table method in Python. For example:
The above example assumes there is a live table named QueryPerformanceLog in the DbInternal namespace, which has a column named Date.
Note that derived tables defined by queries on live tables are also live.
Input tables
Input tables allow you to add, change, or remove data in the table. You can do this either programmatically, or via the user interface in much the same way you would edit a spreadsheet. For example, you can input data directly by clicking on a cell and typing in the values:
The input table user guide provides more detail about the API to add/modify data.
Remote tables
Remote Tables enable you to create local copies of tables from a remote Deephaven worker, which may be running on the same machine or a different machine. This feature eases collaboration between multiple Deephaven users on a team, and eliminates the need to manually create and maintain local copies of tables you want to work with.
The remote table user guides for Groovy and Python provide more detail about the API to access tables remotely.