Input tables
Input tables are customizable database tables designed to store data provided by users. Unlike other tables, users can add, remove, and modify data in input tables via the UI. This makes them similar to spreadsheets. Input table data can also be added, removed, and modified programmatically.
Input tables must contain at least one key column and can include any number of value columns. The key column(s) in input tables are used to update rows. If a new row of data is added and the key value does not already exist in the table, a new row will be created. However, if the key value is already present, the row with that key value will be modified.
Create an input table
The following code creates an Input Table with the following columns:
Symbol: The sole key column of typeString.Exchange: A value column of typeString.MyDoubleCol: A value column of typefloat64(double).MyBooleanCol: A value column of typebool.
You can also manually input the data by clicking on a cell and typing in the values directly, like a spreadsheet.
Create input tables programmatically
This section has some examples of most Input Table methods. For detailed API documentation, please refer to the Javadoc for the WritableDatabase interface or the Pydoc for the Database interface.
Note
The system disallows a mixture of input table and non-input table methods for a given table.
Add input table schema
The above example demonstrated how to add an input table schema by explicitly specifying columns. Alternatively, you can add an input table schema based on another table:
You must manually specify the key columns when adding an input table schema based on another table. You can specify more than one key column by passing in more than one column name:
Input table schemas support the following data types:
| Python | Groovy |
|---|---|
dtypes.string | String.class |
dtypes.Instant | Instant.class |
dtypes.bool_ | Boolean.class |
dtypes.char | char.class |
dtypes.float32 | float.class |
dtypes.float64 | double.class |
dtypes.byte | byte.class |
dtypes.short | short.class |
dtypes.int32 | int.class |
dtypes.long | long.class |
Get an input table from the Deephaven database
The following example gets an input table called InputTableName from the InputTableNamespace namespace:
Update input table schema
Updating an input table schema follows the same pattern as adding and differs only by the method call. However, it's useful to first retrieve the current input table specification before updating.
Add a column
Remove a column
Caution
After adding or removing columns, ensure that any related input tables currently active in your session are reloaded. Otherwise, you won't be able to add, update, or delete rows from the input table view.
Rules for adds and removes
You can add or remove columns in combination, but some updates are prohibited. You cannot:
- Add or remove key columns.
- Change the data type of columns.
- Re-add columns that were previously removed unless the data type is the same as before.
- Change from value column to key column or vice versa.
The add and update methods return a boolean indicating whether the operation succeeded.
Delete data from an input table
The first example adds data programmatically as well as from the UI using a table with the same definition as the input table. The following example programmatically deletes data from an input table by specifying a table containing the key values you want to delete:
You can also do the same using the secondary click in the UI directly.
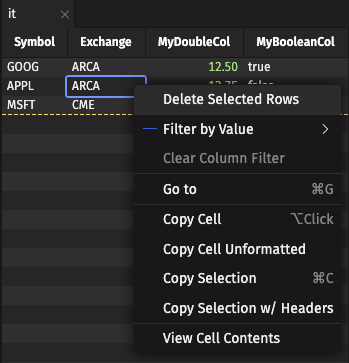
Delete an input table
Warning
Deleting input tables while queries are using those input tables will cause query errors. See Risks of Modifying Live Data for recovery procedures.
The following example deletes an input table:
The delete method returns a boolean indicating whether the input table was deleted.
Interact with input tables using the GUI
You can interact with input tables on the GUI the same way as Legacy input tables.
Implementation details
This section contains lower-level details about how input tables are implemented and some additional APIs for interacting with them.
Input table schema
Input table specifications are retained within the table's schema in the InputTableSpec element. Following is an example schema for "InputTableNamespace.InputTableName", which was updated to first add the column "MyIntCol" and then updated to remove that same column.
Currently, only Keyed input table types are supported for persisted Core+ input tables. You can still create in-memory input tables of keyed or append-only type using the Core API.
version is incremented every time the input table schema is updated.
Note that because "MyIntCol" was removed, it is not listed as a normal Column element, but is retained as a ValueColumn element in the InputTableSpec with the attribute removed="true". This is to prevent users from trying to re-add the column in the future with a different data type, which would cause errors in data interpretation.
You may notice Column elements that are prefixed with an underscore. Every input table has special metadata columns that are available for auditing. The user may not use these special column names:
| Column | Type | Description |
|---|---|---|
| _AuthenticatedUser | String | The authenticated user running the worker. |
| _EffectiveUser | String | The effective user running the worker. |
| _OperationAuthenticatedUser | String | The authenticated user running the operation. |
| _OperationEffectiveUser | String | The effective user running the operation. |
| _ProcessInfoId | String | The unique key for the worker. |
| _EngineVersion | String | The running Core+ version, which contains the Core and Enterprise version. |
| _BatchId | int | The id associated with an input table operation. |
| _ChangeTime | Instant | The time associated with an input table operation. |
| _Deleted | Boolean | Whether the input table operation was a delete or not. |
Note
The authenticated user is the user that authenticated to the system to initiate the operation. The effective user is the user that Deephaven enforces permission checks for.
A simple example is the "Operate as" login, where the user who logs in (via password, SAML, etc.) is the Authenticated User, and the user they are operating as is the Effective User.
Underlying user table
Input tables are backed by live partitioned user tables, although its API differs from partitioned tables. Input table column partitions are the dates of add or delete events based on the system's default time zone. The schema shown in the above example is the schema of the underlying live partitioned user table. It shows the column Date as a partitioning column.
To access the underlying live table directly, run:
This will show you all the columns from the above schema as well as the history of all the operations performed on the input table. Queries that view the input table only use the last row for each key (using lastby() on key columns). This filters out the rows marked as deleted (using where()) and filters out the deleted as well as additional metadata columns.
Input table snapshots
Over time, input table usage can result in a lot of partitions and, therefore, a large fetch-time. To reduce the fetch-time, you can snapshot input tables, which effectively takes the current input table view and writes it into a single partition. From then on, retrieving the input table will only fetch this snapped partition and new data since the snapshot.
The following Groovy example demonstrates how to snapshot input tables:
The following properties can be modified in the Enterprise configuration to control the number of days or modified rows required for a new snapshot to be created. The default values are:
Convert input tables from Legacy to Core+
You can convert a Legacy input table into a Core+ input table from a Core+ worker. Out of caution, the process creates a Core+ input table that copies the latest state of the Legacy input table to a new table name and/or namespace, without affecting the Legacy input table itself. Only the current state of the Legacy input table is transferred to the new table; the history of the Legacy input table is not carried over.
The following query performs the conversion (in Groovy only):
Replace the Legacy input table
After verifying a successful conversion, you may want to delete the original Legacy input table and rename the new Core+ input table to the original name.
To delete the original Legacy input table (removing the data, schema, InputTable configuration, and snapshots), run the following from a Legacy worker in a Groovy console:
To rename the new Core+ input to the original namespace and table name of the Legacy input table, run the following from a Core+ worker:
Renaming the Core+ input table is actually a copy and delete of said Core+ input table.
After verifying a successful copy, you can delete the first Core+ input table from a Core+ worker via: