Data indexes
Indexes are a crucial component in optimizing query performance in large datasets. They allow the system to quickly locate and retrieve the necessary data without scanning the entire dataset. This document covers the different types of indexes used in table storage, including location indexing and grouping, and provides guidance on managing these indexes to ensure efficient data retrieval.
Location indexing (Metadata Indexes)
When queries are performed, the system must locate the data to be queried. This is done by scanning the filesystem to find the data files that match the query. This can be a time-consuming process, especially for tables with many partitions and partition values.
To improve performance, .tlmi files cache all partition values and their locations in a single file per table. This allows the system to find table locations by reading one known file instead of scanning the filesystem, resulting in much faster initial response times for queries against tables with many locations.
Location indexing is enabled by default. Typically, changes to historical data locations occur only when new partition values are written during the merge process. Location indexing can be disabled by setting the LocalMetadataIndexer.ENABLED property to false:
Note
Hive format tables must use a Locations table instead of .tlmi index files.
Index Management
Location Indexes may be manually updated, validated, and listed using the dhctl metadata tool.
Common commands include:
Index all System tables:
Index all the tables within the System namespace ExampleNamespace:
Index the System table ExampleTable in ExampleNamespace:
Rerunning the indexer command on a system that has already been indexed will replace the .tlmi files with refreshed versions, even if nothing has changed.
Grouping
When a table is grouped, the data is organized by one or more columns. Grouping is similar to partitioning, but the data is not split into separate files. Instead, the data is organized within a single file or set of files.
Grouping is a specialized form of data index. The engine leverages grouping columns as data indexes to optimize query performance, similar to other data indexes. Additionally, grouping provides two extra benefits:
- Locality - Filtering by grouping columns often improves data locality on disk, making retrieval operations more efficient.
- Implied Filtering - Filtering on a grouping column inherently filters all preceding grouping columns, reducing redundancy in query filters.
Tables can have one or more grouping columns. If there are multiple grouping columns, the groups must form a tree. Each group in the second column must belong to exactly one group in the first column, and so on.
If you had a table of names, you could group by LastName or FirstName, but you couldn't group by FirstName and LastName because multiple people can have the same first name and different last names or vice versa.
Here's an example of a valid multiply-grouped table with grouping columns UnderlyingTicker and Ticker:

Here's an example of an invalid multiply-grouped table with grouping columns LastName and FirstName:
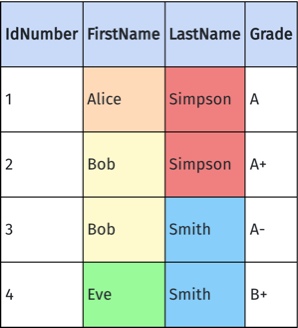
Enable Grouping
Table data can be grouped when merging intraday data for system namespaces to historical data. This is done by setting the grouping property in the schema file. Ensure you deploy the schema so that the changes take effect.
Engine and Schema Data Indexes
In addition to the metadata and grouping indexes described above, Deephaven supports general-purpose data indexes that can be created on tables to optimize query performance. These indexes are distinct from the table storage metadata indexes and grouping optimizations.
For detailed information on creating and using data indexes in the Deephaven engine, see:
- Core data indexes guide - Comprehensive guide on creating and using data indexes in queries
- Schema data indexes - How to configure data indexes in schema definitions
These indexes can significantly improve query performance by allowing the engine to quickly locate rows matching specific criteria without scanning entire tables.