An Overview of Deephaven's Architecture
Deephaven's power is largely due to the concept that everything is a table. Think of Deephaven tables like Pandas DataFrames, except that they support real-time operations! The Deephaven table is the key abstraction that unites static and real-time data for a seamless, integrated experience. This section will discuss the conceptual building blocks of Deephaven tables before diving into some real code.
The Deephaven Table API
If you're familiar with tabular data (think Excel, Pandas, and more), Deephaven will feel natural to you. In addition to representing data as tables, you must be able to manipulate, transform, extract, and analyze the data to produce valuable insight. Deephaven represents transformations to the data stored in a table as operations on that table. These table operations can be chained together to generate a new perspective on the data:
This paradigm of representing data transformations with methods that act on tables is not new. However, Deephaven takes this a step further. In addition to its large collection of table operations, Deephaven provides a vast library of efficient functions and operations, accessible through query strings that get invoked from within table operations. These query strings, once understood, are a superpower that is totally unique to Deephaven. More on these later.
Collectively, the representation of data as tables, the table operations that act upon them, and the query strings used within table operations are known as the Deephaven Query Language, or DQL for short. The data transformations written with DQL (like the code above) are called Deephaven queries. The fundamental principle of the Deephaven experience is this:
Deephaven queries are unaware and indifferent to whether the underlying data source is static or streaming.
The magic here is hard to overstate. The same queries written to parse a simple CSV file can be used to analyze a similarly fashioned living dataset, evolving at millions of rows per second, without changing the query itself. Real-time analysis doesn't get simpler.
Immutable schema, mutable data
When Deephaven tables are created, they follow a well-defined recipe that cannot be modified after creation. This means that the number of columns in a table, the column names, and their data types - collectively known as the table's schema - are immutable. Even so, the data stored in a table can change. Here's a simple example that uses time_table:
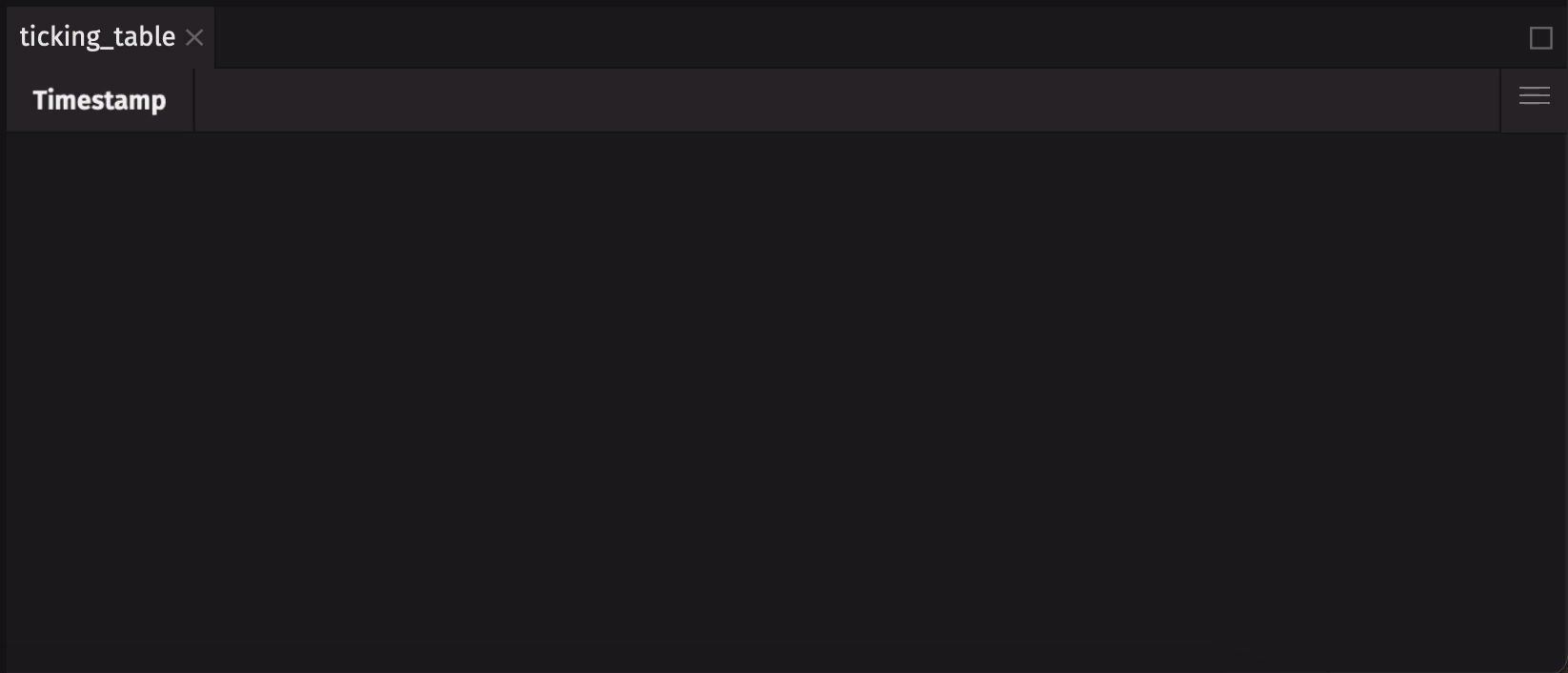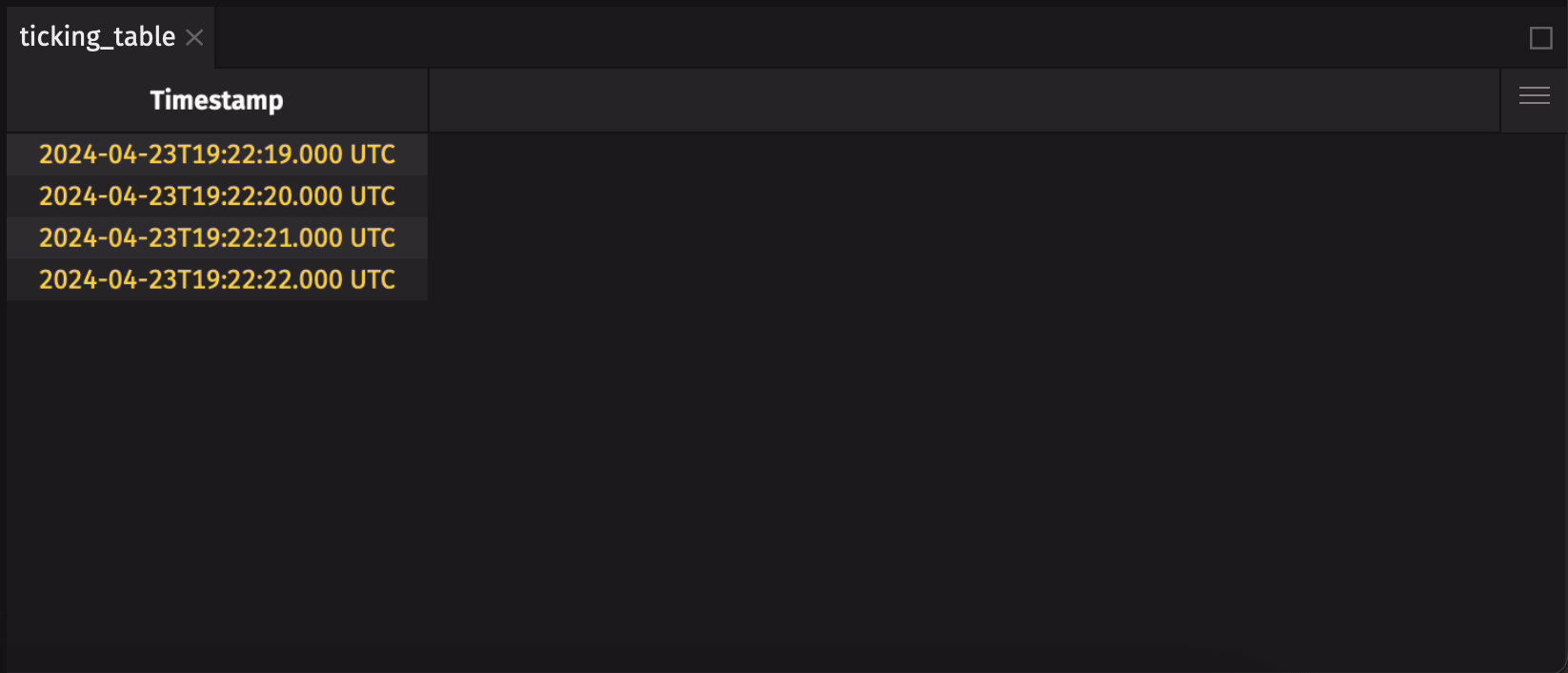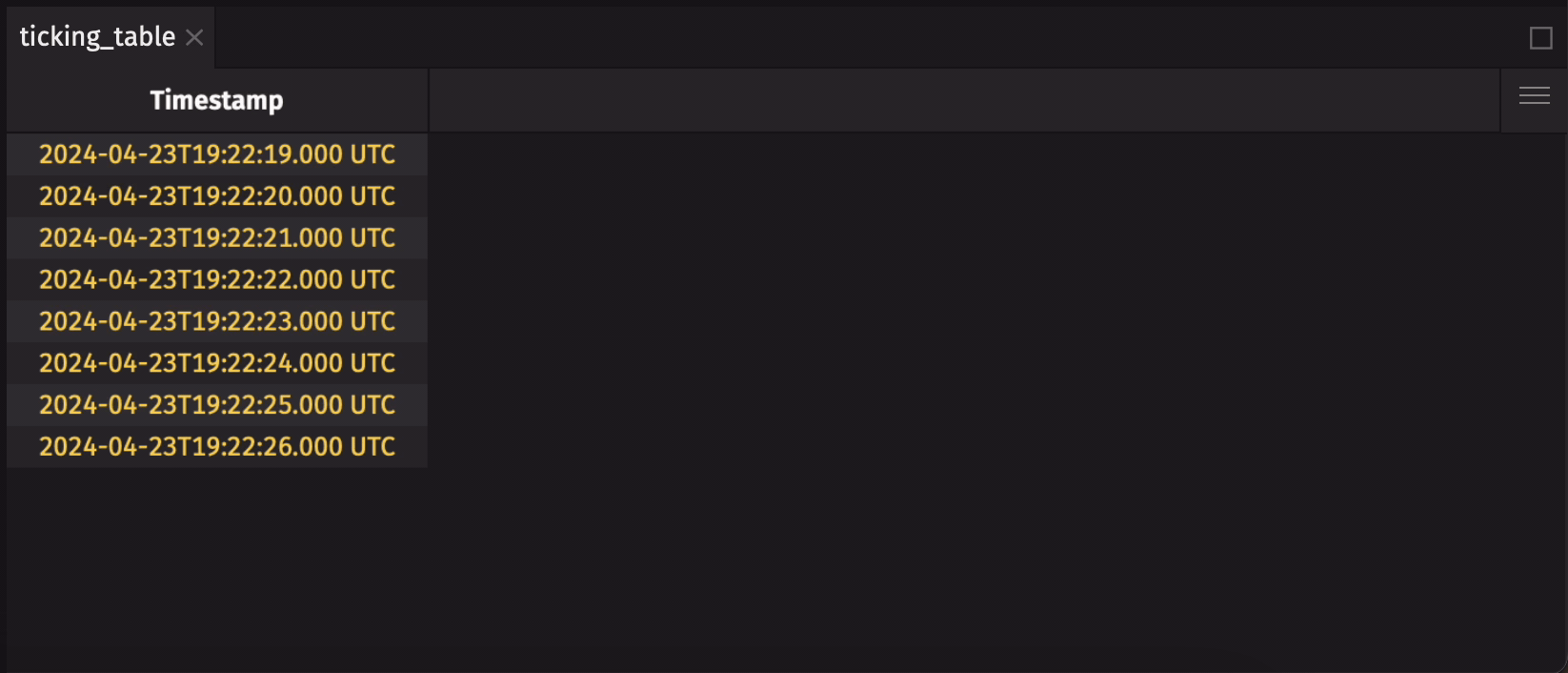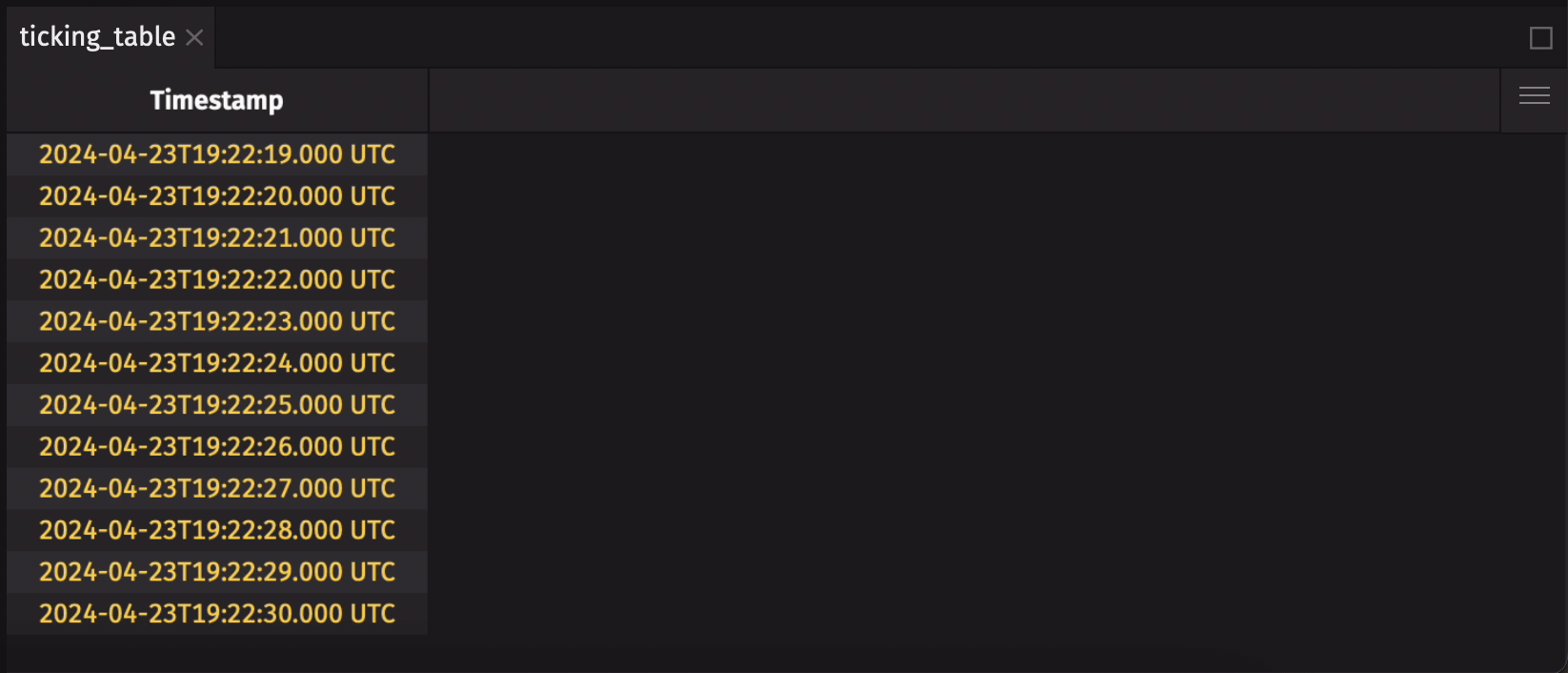
New data is added to the table each second, but the schema stays the same.
Some queries appear to modify a table's schema. They may add or remove a column, modify a column's type, or rename a column. For example, the following query appears to rename the Timestamp column in the table to RenamedTimestamp:
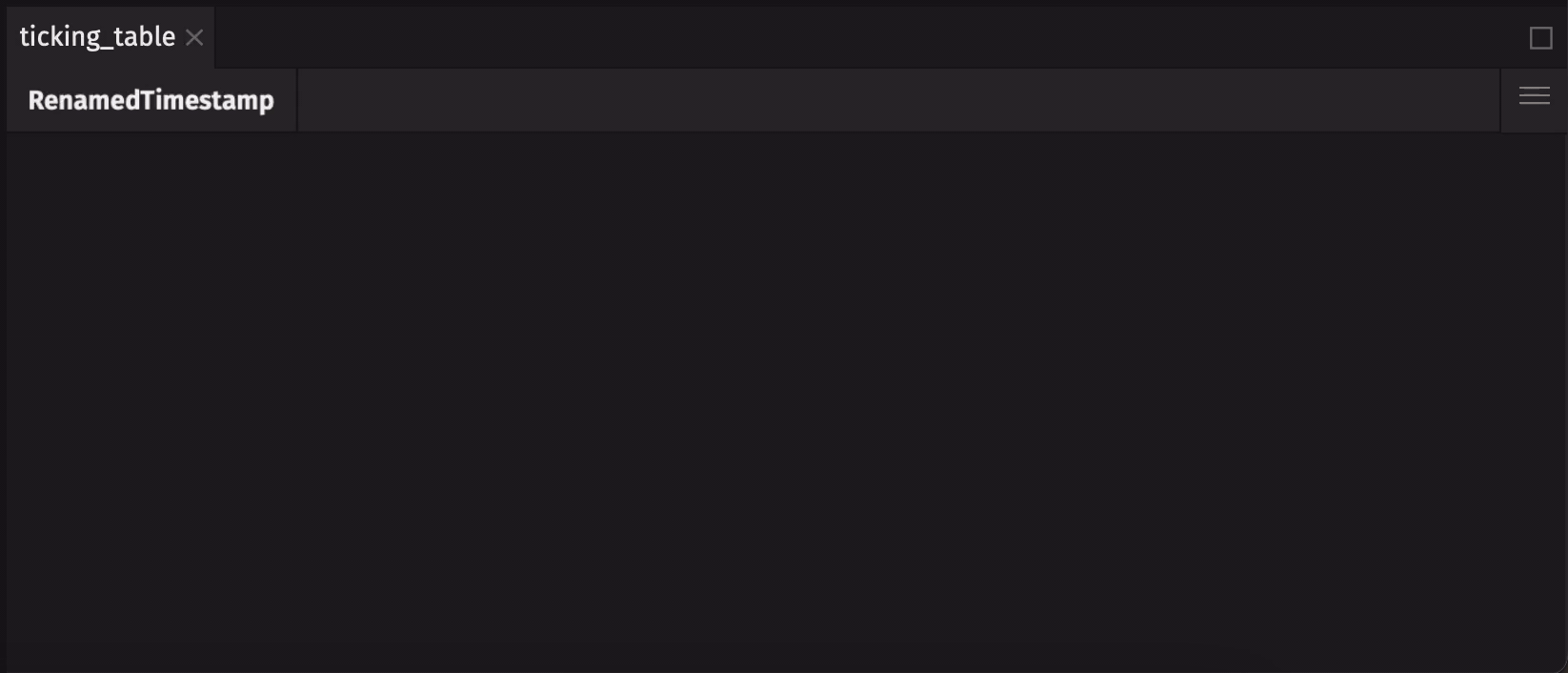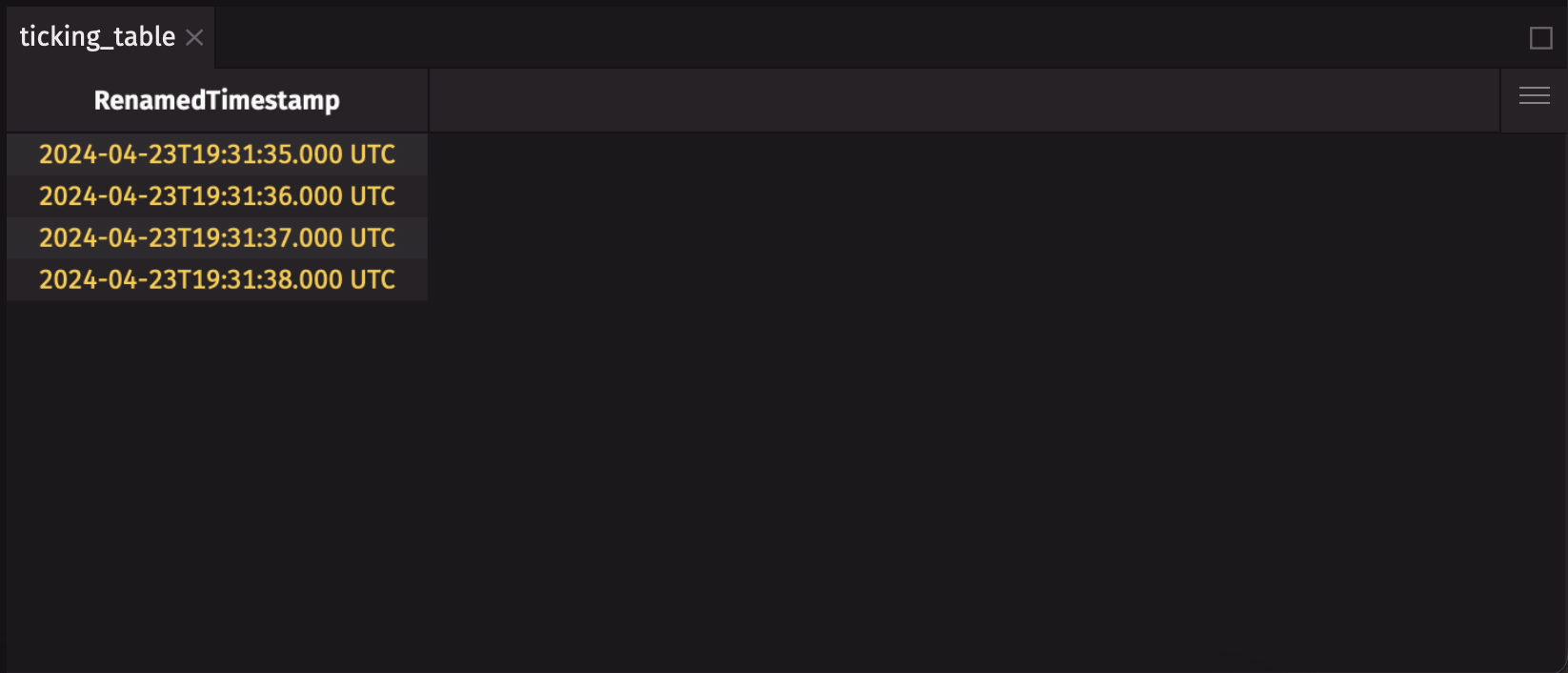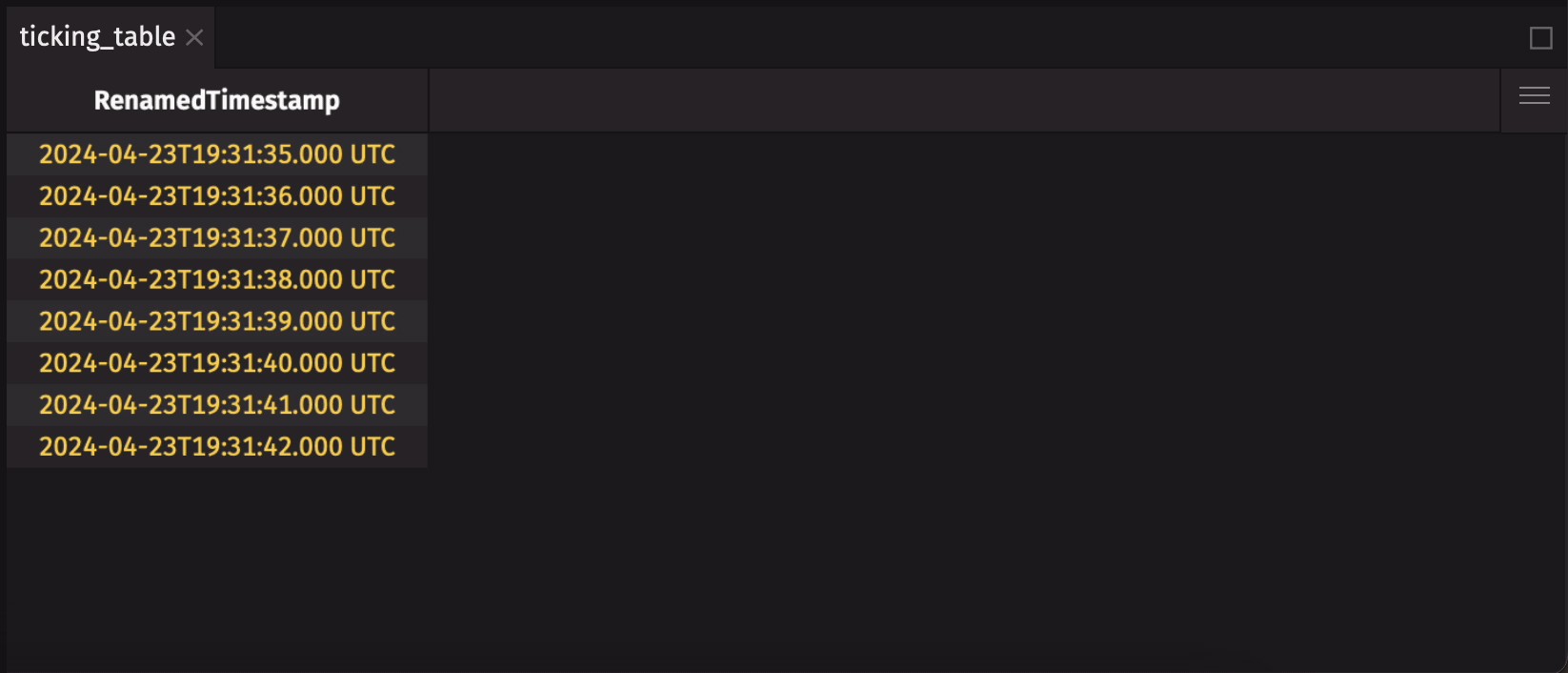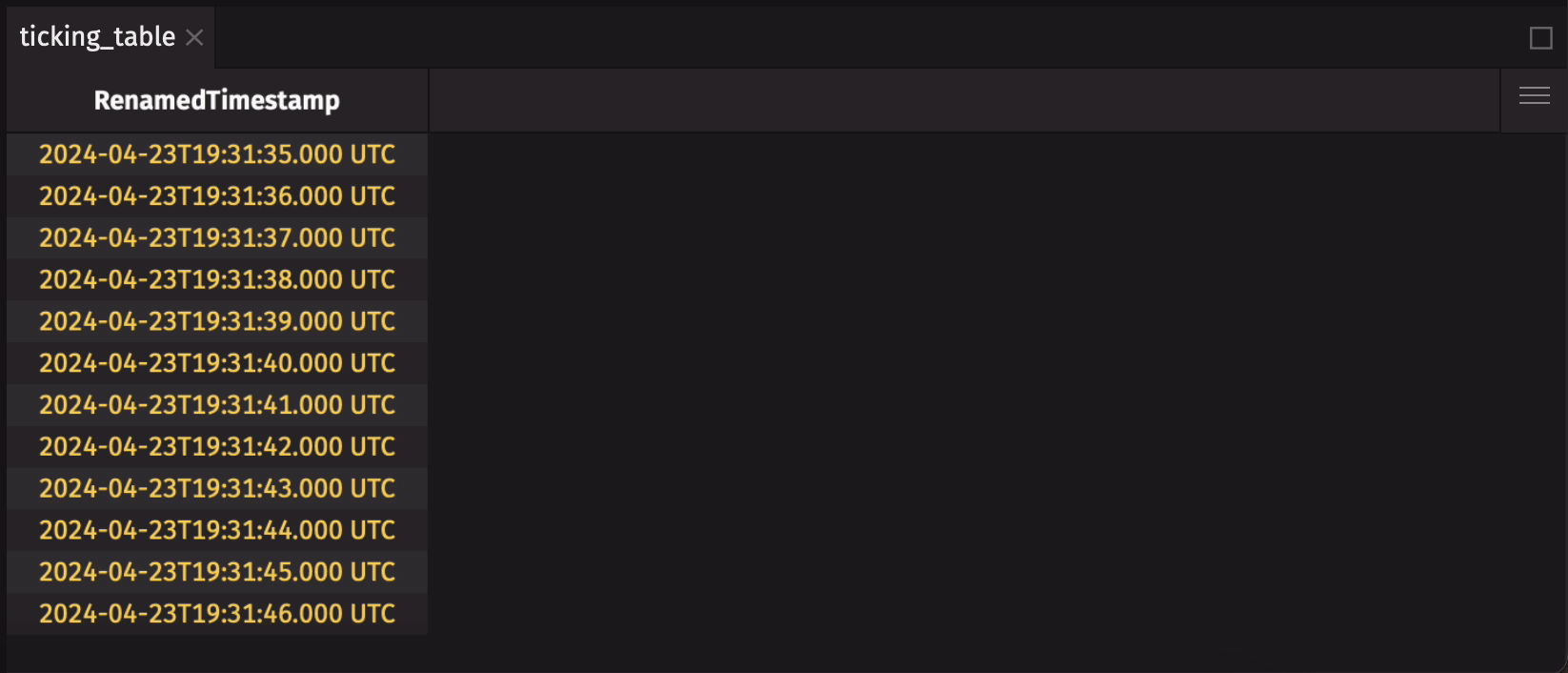
Since the schema of ticking_table is immutable, its columns cannot be renamed. Instead, Deephaven creates a new table with a new schema. Deephaven is smart about creating the new table so that only a tiny amount of additional memory is used to make it. An important consequence of this design is that Deephaven does not support in-place operations:
See how that operation has no effect. Instead, always assign the output of any table operation to a new table, even if it has the same name:
The engine
The Deephaven engine is the powerhouse that implements everything you've seen so far. The engine is responsible for processing streaming data as efficiently as possible, and all Deephaven queries must flow through the engine.
Internally, the engine represents queries as directed acyclic graphs (DAGs). This representation is key to Deephaven's efficiency. When a parent (upstream) table changes, a change summary is sent to child (downstream) tables. This compute-on-deltas model ensures that only updated rows in child tables are re-evaluated for each update cycle and allows Deephaven to process millions of rows per second.
For the sake of efficiency and scalability, the engine is implemented mostly in Java. Although you primarily interface with tables and write queries from Python, all of the underlying data in a table is stored in Java data structures, and all low-level operations are implemented in Java. Most Deephaven users will interact with Java at least a little bit, and there are important things to consider when passing data between Python and Java.
User interface
The Deephaven user interface (UI) is a web-based application that runs in your browser. It is built with React and TypeScript and communicates with the Deephaven engine using the JavaScript API. The UI provides a rich experience for exploring tables, writing queries, and visualizing data.
Using deephaven.ui, you can create interactive web applications that leverage the power of Deephaven tables directly from your Python code. The deephaven.ui library provides a set of React components and hooks that make it easy to build custom dashboards, data explorers, and visualizations. You can use these components to display tables, create charts, and interact with data in real-time.
The UI is also highly extensible. You can add custom widgets, visualizations, and functionality using JavaScript plugins. These plugins can be installed in your Deephaven server configuration and will be automatically loaded when the server starts. Create your own plugin starting with one of the plugin templates available on GitHub.
All components of the Deephaven UI are published as packages to npmjs under the @deephaven and @deephaven-enterprise organizations. These packages can be used and installed in your own web applications. Example React applications that use the Deephaven UI components are available in the deephaven-react-app and deephaven-react-app-enterprise repositories.
In addition to publishing the packages, all Core components of the UI are available open-source on GitHub in the deephaven/web-client-ui repository. Source code for the plugins is at deephaven/deephaven-plugins. You can explore the source code, contribute to the project, or even fork it to create your own custom version of the Deephaven UI.