Triage errors in queries
This guide will show you how to interpret query errors and exception messages.
As with any programming language, when writing queries in Deephaven Query Language, you will certainly make mistakes. Mistakes will often result in queries failing to start up properly or crashing at some point during their runtime. Here, we provide a set of best practices to use when interpreting and fixing these issues.
Simple triage
At this point, you have written some Deephaven queries that should produce some interesting tables and visualizations, but when you attempt to run the query, it fails.
The first step is to find the error (referred to as an Exception) and isolate its root cause. This will usually appear in the log panel.
The log will display a large block of text that describes the exception and a chain of further exceptions that leads to the root of the problem.
Tip
Identify the root cause by looking at the caused by statements. Start from the last exception in the chain and work backwards.
For example, we'll start by creating a function that generates an error, then a table that invokes it, with the following commands:
The query fails with the following error:
Deephaven stack traces tend to be very large, but lead off with a summation of the underlying error. Look at the first few lines of the above stack trace:
There are two important lines from this error message:
Value: table update operation failed. : Value: Error: 0- This line contains the value error the function was told to raise.
RuntimeError: io.deephaven.engine.exceptions.TableInitializationException: Error while initializing Update([X]): an exception occurred while performing the initial select or update- This tells us the error was made during an
updateoperation. - This also tells us that the column name that caused the error is
X.
- This tells us the error was made during an
Scroll past the first block of indented lines saying at io.deephaven...; there's some more important information:
Most lines in the above block of stack trace indicate what's going on, but these two point to exactly where the error happens:
Line: 5File "<string>", line 5, in throw_func
Both of these tell us that the query errored on line 5, which is the same line where the RuntimeError gets thrown.
When triaging errors in Deephaven Python queries, there are a few rules of thumb to follow that can help make it easier:
- The important details are rarely at the bottom of the stack trace.
- The first few lines, like above, have information that can be used to identify the cause.
- The important information is typically in blocks of text that are not indented. Indented text points to the underlying Java.
This is a very simple example of triaging an equally simple query with deliberate errors. In practice, queries will be much more sophisticated and contain many interdependencies between tables. The recipe for triage, however, is the same.
See the sections below for examples of some common mistakes.
Common mistakes
Once you've fixed the static problems, your query will start serving up tables and plots. Sometimes the query may crash unexpectedly during its normal runtime. These problems can be trickier to triage because they will often be related to unexpected streaming data patterns.
Your first steps should be the same as for a startup error:
- Start at the top.
- Skim over indented blocks of text.
- Look for Python-specific exceptions.
The Console in the Deephaven IDE is a critical tool during this process. Once you've isolated the failing operation, you can execute parts of the query bit by bit to analyze the inputs to the failing method and experiment with changes to solve the problem.
Below we will discuss some of the most common categories of failure.
Unexpected null values
It's easy to forget that columns can contain null values. If your queries don't account for this, they will fail with a NullPointerException.
The following shows a simple dataset consisting of a string column with a null value. It attempts to grab strings that start with B using the charAt method.
In this example, the following information can be found in the first few lines of the stack trace:
As discussed above, using the Console is a good way to inspect the tables for this condition.
In this case, we must check if the value we are trying to inspect is null:
Note
Adding !isNull(Items) to the start of our filter statement works because of boolean short circuiting. In this example, when !isNull(Items) is false, the query will stop evaulating the remainder of the where clause, meaning the problematic Items.charAt(0) == 'B' statement is never executed on a null value.
String and array access
Accessing strings or arrays may also present difficulties. You may need to classify rows based upon the value of a character within a string of expected size; operations such as group_by will produce cells that contain arrays of values. It's possible you might try to access a value in one of these types that does not exist.
The following example shows a simple dataset consisting of a string column with strings of varying length. It attempts to grab strings that have i as the second character.
Like the previous examples, the root cause can be found in the first few lines of the stack trace:
This line contains the actual query string that caused the error, making it clear which line is the culprit.
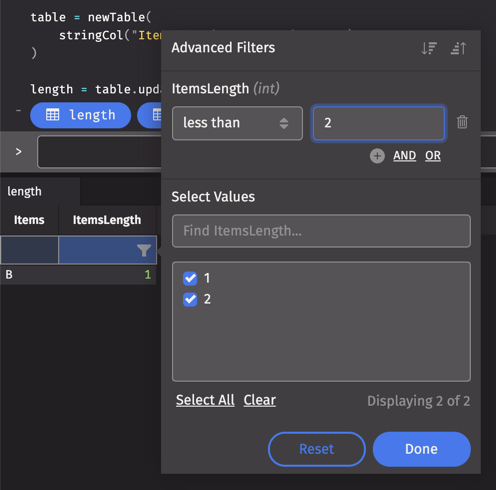
We can inspect the table by adding a new column ItemsLength = Items.length():
To see rows where the string is less than two characters long, filter that table to only rows where ItemsLength < 2 using the right-click menu results:
Following the advice above, let's change the query to:
This works due to Java's boolean short circuiting described above.
If you really only care about the presence of the i character in the string, a better solution is:
As always, use the Deephaven IDE to validate that this change works and produces the result you expect!
Join key problems
Deephaven's join operations are one of its most powerful features. They merge tables together based upon matching parameters to produce new tables.
Some flavors of join are tolerant to the cardinality of key instances on the left and right hand sides, but some are not. natural_join, for example, requires that there is no more than one right hand side key mapped to every left hand side key. This causes issues when the input data to a joined table does not adhere to these requirements. Below is a query that exhibits this behavior.
Because 31 appears twice in the DeptID column in the right table, the following error will be thrown:
Non-deterministic formulas
Not all errors have stack traces. For instance, the use of non-deterministic functions in formula columns can lead to undefined results. A deterministic algorithm is one that produces the exact same result every single time when given the same input parameters. A simple example of a non-deterministic function is a random number generator. Consider the following query:
Notice how the NumberTimesTwo column contains values that are all even, but not two times what's in the Number column. This is because update_view was used with a random number generator. An update_view creates a formula column, which only stores the formula and calculates values on-demand. So, the values are calculated in Number, then re-calculated when computing NumberTimesTwo. Thus, NumberTimesTwo has two times a completely different random number. Errors like these can be trickier to diagnose, so it's important to be cognizant of what type of columns are created when using any non-deterministic functions.
Out of memory
One of the most common problems with a query can be a lack of memory (referred to as heap) to handle a query as the data volume grows throughout the day. This occurs if enough heap is not allocated to your Deephaven instance but can be exacerbated by unexpected data patterns, like unusually large Kafka input. Most often this can be fixed by increasing the heap allocated to Deephaven, but an analysis of the query itself may yield improvements to the script that reduces overall heap usage.
Below is the most common example of Out Of Heap failures:
Caused by: java.lang.OutOfMemoryError: Java heap space
There are many ways to approach this problem and, in practice, resolution will require some combination of all of the techniques mentioned below.
The first, and simplest, action to take is to increase the heap allocated to your Java Virtual Machine. Using the Docker-based example provided by Deephaven in the Docker install guide, you could simply increase the amount of memory allocated to Docker, up to certain limits. If you are using the Docker-based example and want to adjust the memory allocation, please see the file docker-compose-common.yml in your Deephaven Core base directory.
For many workloads this will be enough. However, users must be aware that you may not get the results you expect when you increase memory across the 32GB boundary. Java uses address compression techniques to optimize memory usage when maximum heap size is smaller than 32GB. Once you request 32GB or more, this feature is disabled so that the program can access its entire memory space. This means that if you start with 30GB of heap and then increase the size to 32GB, you will have less heap available to your query.
Tip
If you must cross the 32GB boundary, it is best to jump directly to 42GB to account for this.
The next step is to review your query code.
- Look for places where you use
update. Wouldupdate_viewbe better? Keep in mind formula stability. The choice betweenupdateandupdate_viewis a memory vs. CPU tradeoff. You will pay more in CPU time withupdate_viewin order to save on memory. For simple computations and transformations, this is often a very good tradeoff. See our guide, Choose the right selection method. - Search for duplicate tables, or tables that only differ in column count. Try to re-use tables in derivative computations as much as possible to make use of the query's previous work. In most cases, Deephaven automatically recognizes duplicate computations and uses the original tables. However, it is best not to rely on this behavior and instead be explicit about what tables you derive from.
- When using Deephaven query expressions that group rows based on keys (
partition_by,group_by, andjoinoperations), pay close attention to the number of unique keys in the tables you apply these operations to. If keys are generally unique (SaleID, for example) within a table, then an operation likepartition_bywill produce potentially millions of single row tables that all consume some heap space in overhead. In these cases, consider if you can use different keys, or even a different set of Deephaven query operations. - Carefully consider the order you execute Deephaven query expressions. It’s best to filter data before joining tables.
- A very simple example is applying a
joinand awherecondition. If you were to executederived = myTable.join(myOtherTable, “JoinColumn”).where(“FilterColumn=`FilterValue`), thejoinoperation consumes much more heap than it needs to, since it will take time matching rows frommyTablethat would later be filtered down in thewhereexpression. - This query would be better expressed as
derived = myTable.where(“FilterColumn=`FilterValue`).join(myOtherTable, “JoinColumn”). This saves in heap usage, but also reduces how many rows are processed in downstream tables (called ticks) when the left hand or right hand tables tick.
- A very simple example is applying a
There are many other reasons that a query may use more heap than expected. This requires a deep analysis of how the query is performing at runtime. You may need to use a Java profiling tool (such as JProfiler) to identify poorly-performing sections of your code.
Garbage Collection (GC) timeouts
GC timeouts are another type of heap-related problem. These occur when you have enough memory for your query, but lots of data is being manipulated in memory each time your data ticks. This can happen, for example, when performing a long series of query operations. This results in lots of temporary heap allocation to process those upstream ticks. When the upstream computations are done, the JVM can re-collect that memory for use in later calculations. This is called the 'Garbage Collection' phase of JVM processing. Garbage Collection consumes CPU time, which can halt your normal query processing and cause computations to back up even further.
This behavior is characterized by periodic long pauses as the JVM frees up memory. When this happens, look for ways to reduce your tick frequency.
Get help
If you've gone through all of the steps to identify the root of a problem, but can’t find a cause in your query, you may have uncovered a bug. In this case, you should file a bug report. Be sure to include the following with your bug report:
- The version of the Deephaven system.
- The complete stack trace, not just the list of
Caused Byexpressions. - A code snippet or a description of the query.
- Any logs from your user console or, if running Docker, from your terminal.
- Support logs exported from the browser. In the Settings menu, click the Export Logs button to download a zip with the browser logs and the current state of the application.
You can also get help by asking questions in our GitHub Discussions forum.
Appendix: Common errors in queries
- Is your Deephaven query expression properly quoted?
- Expressions within Deephaven query statements such as
whereorupdatemust be surrounded by double quotes. For example,myTable.where(filters=["StringColumn=`TheValue`"]). - If you copy-pasted an expression from somewhere (e.g., Slack), some systems will copy a unicode double quotation (U+201C and U+201D) instead of an ASCII quotation (U+0022).
-
Do you have matching parentheses?
- Make sure that any open parenthesis that you are using are matched by a close parenthesis.
-
If you are referring to a column in a Deephaven query expression:
- Check the spelling and capitalization.
- Is the type of the column what you expect it to be?
- Did you account for null values?
-
If you are using strings in your expression, did you quote them properly?
- Strings are quoted with the backtick character (
`), not single quotes (‘) or double quotes ("). - Do you have matching close quotes for your open quotes?
- Strings are quoted with the backtick character (
-
If you are using date-times in your expressions:
- Did you use single quotes (
‘), not double quotes (“) or backticks (`)? - Did you use the proper format? Deephaven date-times are expected as
<yyyyMMDD>T<HH:mm:ss.nnnnnnnnn> <TZ>.
- Did you use single quotes (
-
Are all classes that you are trying to use properly imported?
- will not search for classes Groovy that you use. If they are not part of the standard set of Deephaven imports, you must import them yourself.