Single aggregation
This guide will show you how to compute summary information on groups of data using dedicated data aggregations.
Often when working with data, you will want to break the data into subgroups and then perform calculations on the grouped data. For example, a large multi-national corporation may want to know their average employee salary by country, or a teacher might want to calculate grade information for groups of students or in certain subject areas.
The process of breaking a table into subgroups and then performing a single type of calculation on the subgroups is known as "dedicated aggregation." The term comes from most operations creating a summary of data within a group (aggregation) and from a single type of operation being computed at once (dedicated).
Deephaven provides many dedicated aggregations, such as max_by and min_by. These aggregations are good options if only one type of aggregation is needed. If more than one type of aggregation is needed or if you have a custom aggregation, combined aggregations are a more efficient and more flexible solution.
Syntax
The general syntax follows:
The by = ["GroupingColumns"] parameter determines the column(s) by which to group data.
DEDICATED_AGGshould be substituted with one of the chosen aggregations below.[]uses the whole table as a single group.["X"]will output the desired value for each group in columnX.["X", "Y"]will output the desired value for each group designated from theXandYcolumns.
Single aggregators
Each dedicated aggregator performs one calculation at a time:
abs_sum_by- Sum of absolute values of each group.avg_by- Average (mean) of each group.count_by- Number of rows in each group.first_by- First row of each group.group_by- Group column content into vectors.head_by- Firstnrows of each group.last_by- Last row of each group.max_by- Maximum value of each group.median_by- Median of each group.min_by- Minimum value of each group.std_by- Sample standard deviation of each group.sum_by- Sum of each group.tail_by- Lastnrows of each group.var_by- Sample variance of each group.weighted_avg_by- Weighted average of each group.weighted_sum_by- Weighted sum of each group.
In the following examples, we have test results in various subjects for some students. We want to summarize this information to see if students perform better in one class or another.
first_by and last_by
In this example, we want to know the first and the last test results for each student. To achieve this, we can use first_by to return the first test value and last_by to return the last test value. The results are grouped by Name.
The last_by operation creates a new table containing the last row in the input table for each key.
The "last" row is defined as the row closest to the bottom of the table. It is based strictly on the order of the rows in the source table — not an aspect of the data (such as timestamps or sequence numbers) nor, for live-updating tables, the row which appeared in the dataset most recently.
A related operation is agg.sorted_last, which sorts the data within each key before finding the last row. When used with agg_by, agg.sorted_last takes the column name (or an array of column names) to sort the data by before performing the last_by operation to identify the last row. It is more efficient than .sort([<sort columns>]).last_by([<key columns>]) because the data is first separated into groups (based on the key columns), then sorted within each group. In many cases this requires less memory and processing than sorting the entire table at once.
The most basic case is a last_by with no key columns. When no key columns are specified, last_by simply returns the last row in the table:
When key columns are specified (such as MyKey in the example below), last_by returns the last row for each key:
You can use multiple key columns:
Often, last_by is used with time series data to return a table showing the current state of a time series. The example below demonstrates using last_by on time series data (using generated data, including timestamps generated based
on the current time).
When data is out of order, it can be sorted before applying the last_by. For example, the data below is naturally ordered by Timestamp1. In order to find the latest rows based on Timestamp2, simply sort the data before running the last_by:
If the sorted data is not used elsewhere in the query, a more efficient implementation is to use agg.sorted_last. This produces the same result table (t2) with one method call (and more efficeint processing of the sort step):
head_by and tail_by
In this example, we want to know the first two and the last two test results for each student. To achieve this, we can use head_by to return the first n test values and tail_by to return the last n test values. The results are grouped by Name.
count_by
In this example, we want to know the number of tests each student completed. count_by returns the number of rows in the table as grouped by Name and stores that in a new column, NumTests.
Summary statistics aggregators
In the following examples, we start with the same source table containing students' test results as used above.
Caution
Applying these aggregations to a column where the average cannot be computed will result in an error. For example, the average is not defined for a column of string values. For more information on removing columns from a table, see drop_columns. The syntax for using drop_columns is result = source.drop_columns(cols=["Col1", "Col2"]).sum_by(by=["Col3", "Col4"]).
sum_by
In this example, sum_by calculates the total sum of test scores for each Name. Because a sum cannot be computed for the string column Subject, this column is dropped before applying sum_by.
avg_by
In this example, avg_by calculates the average (mean) of test scores for each Name. Because an average cannot be computed for the string column Subject, this column is dropped before applying avg_by.
std_by
In this example, std_by calculates the sample standard deviation of test scores for each Name. Because a sample standard deviation cannot be computed for the string column Subject, this column is dropped before applying std_by.
var_by
In this example, var_by calculates the sample variance of test scores for each Name. Because sample variance cannot be computed for the string column Subject, this column is dropped before applying var_by.
median_by
In this example, median_by calculates the median of test scores for each Name. Because a median cannot be computed for the string column Subject, this column is dropped before applying median_by.
min_by
In this example, min_by calculates the minimum of test scores for each Name. Because a minimum cannot be computed for the string column Subject, this column is dropped before applying min_by.
max_by
In this example, max_by calculates the maximum of test scores for each Name. Because a maximum cannot be computed for the string column Subject, this column is dropped before applying max_by .
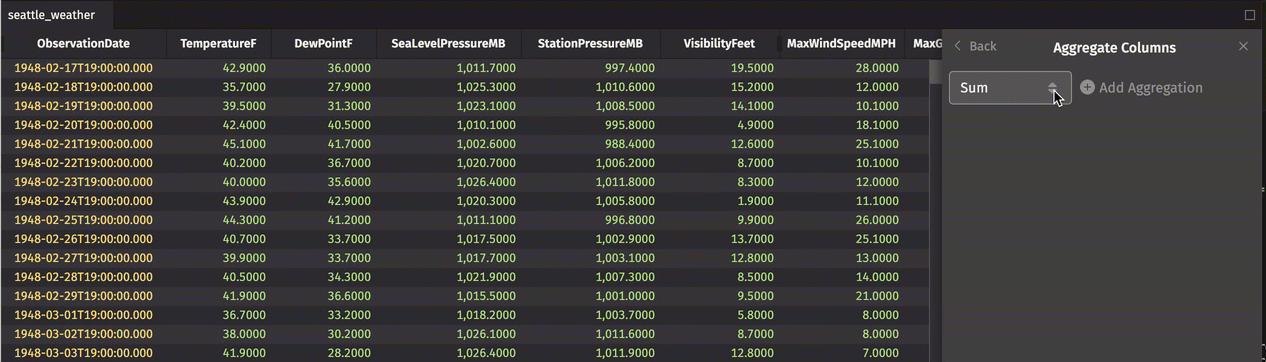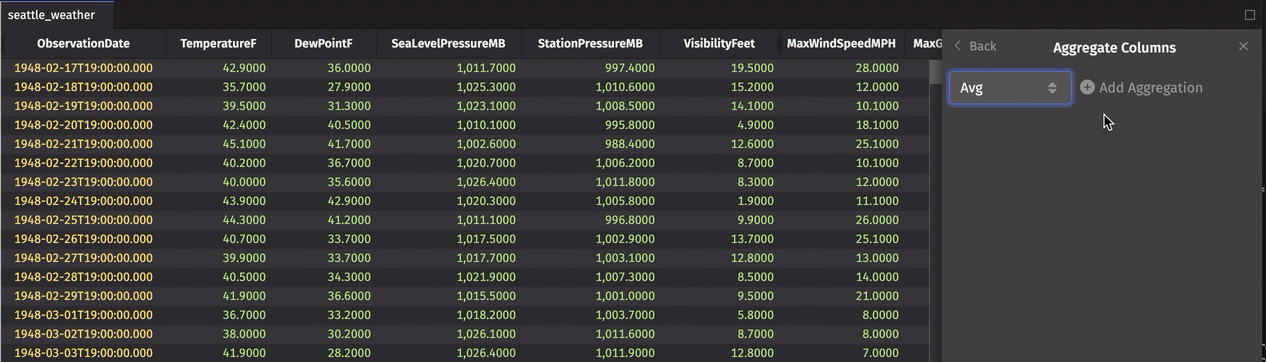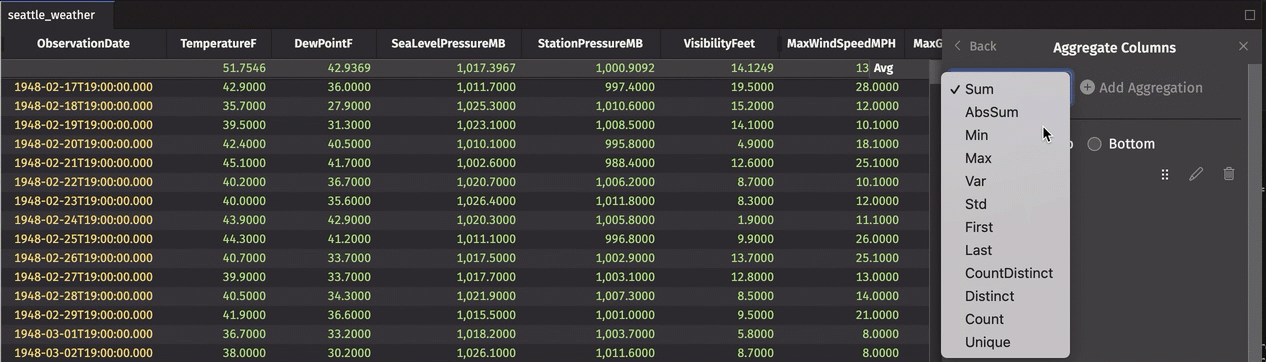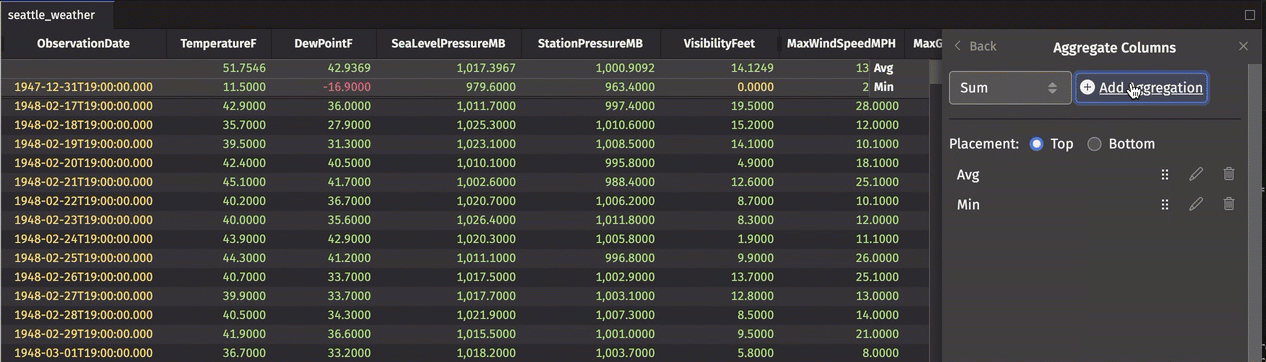
Aggregate columns in the UI
Single aggregations can be performed in the UI using the Aggregate Columns feature. However, rather than adding the aggregation in its own column as shown in the programmatic examples above, the aggregation is added as a row to the top or bottom of the table. Column data is aggregated using the operation of your choice. This is useful for quickly calculating the sum, average, or other aggregate of a column.
In the example below, we add an Average row and a Minimum row to the top of the table:
These aggregations can be re-ordered, edited, or deleted from the Aggregate Columns dialog.