Powerful Python Integrations
Deephaven empowers Python developers by providing efficient integrations with popular Python libraries. This section covers some highlights of Deephaven's Python interoperability as well as the inherent limitations of static Python data structures.
Pandas
The deephaven.pandas module is the gateway to Pandas interoperability. The module itself is simple, containing only two functions: to_pandas, which converts a Deephaven table into a Pandas DataFrame, and to_table, which converts a Pandas DataFrame into a Deephaven table.
The appropriate column types are automatically inferred.
Pandas operations can be applied to the DataFrame and the result can be converted back to a Deephaven table.
Using DQL to do this particular job would be more efficient, but this example demonstrates the flexibility of the Pandas integration.
Note that Pandas DataFrames are inherently static. Converting a ticking Deephaven table to a Pandas DataFrame snapshots the table at that moment in time.
NumPy
NumPy is one of Python's most popular packages. It implements arrays and array operations. Deephaven's deephaven.numpy package, like the Pandas package, contains only two functions, to_numpy and to_table, for converting to and from NumPy arrays and Deephaven tables, respectively.
Note: in this example, the X column is cast from a long to a double. NumPy arrays can only contain a single data type, while Deephaven tables can contain one data type per column. To create a NumPy array, all columns must be the same type. For example, the following conversion will fail.
Listener-based AI
Deephaven makes real-time AI inference easy. Evaluate complex machine learning models on real-time data streams with Deephaven's table listeners and table publishers.
Listener-based AI workflows use a table listener to keep track of a table's changes. Data from these changes is then used as inputs for an AI model. Then, the results are published to an AI results blink table using a table_publisher. Finally, these blink table results are combined into a complete AI inference history using blink_to_append_only.
Here's an example using a synthetic ticking dataset and a simple "model".
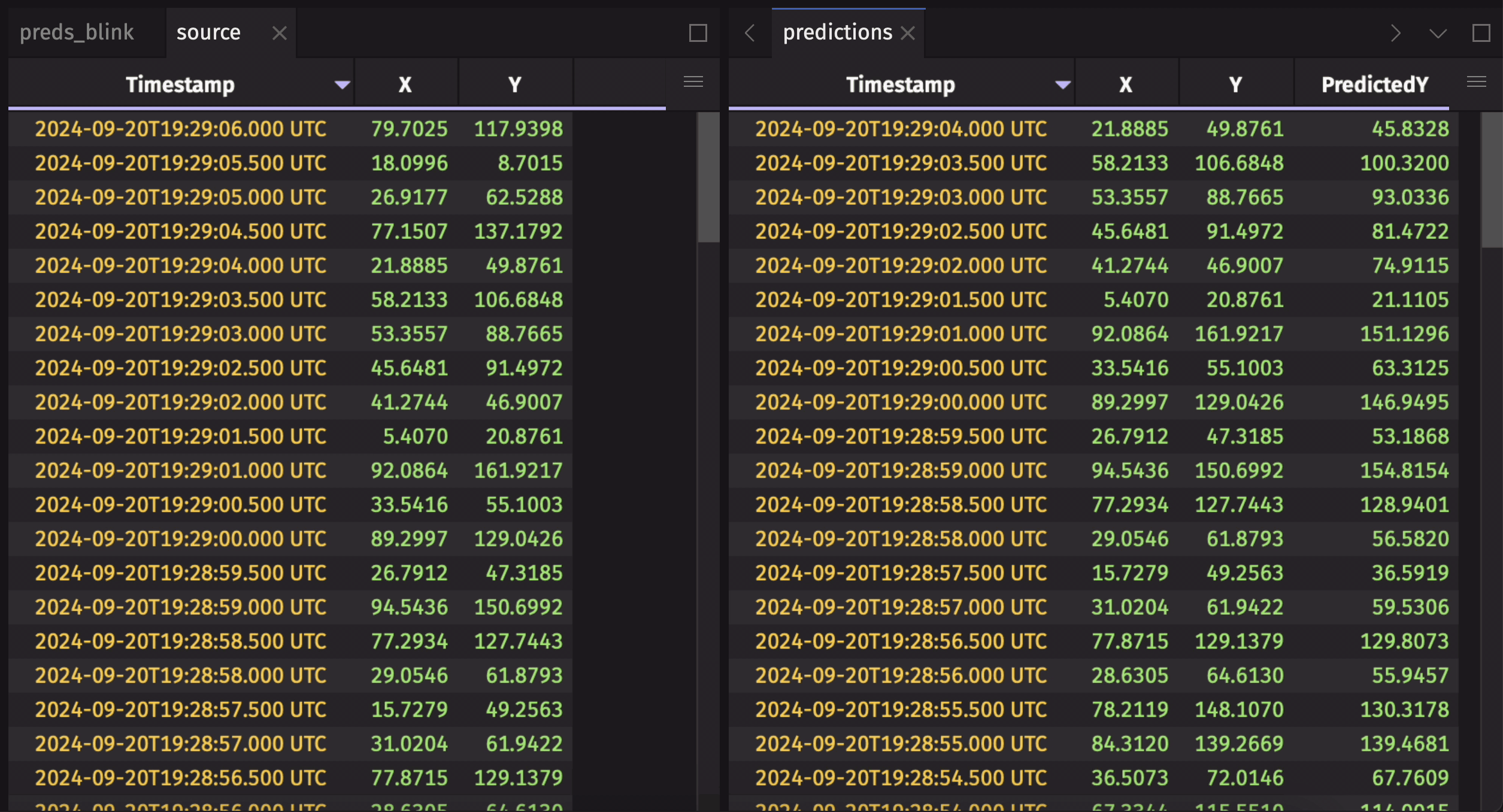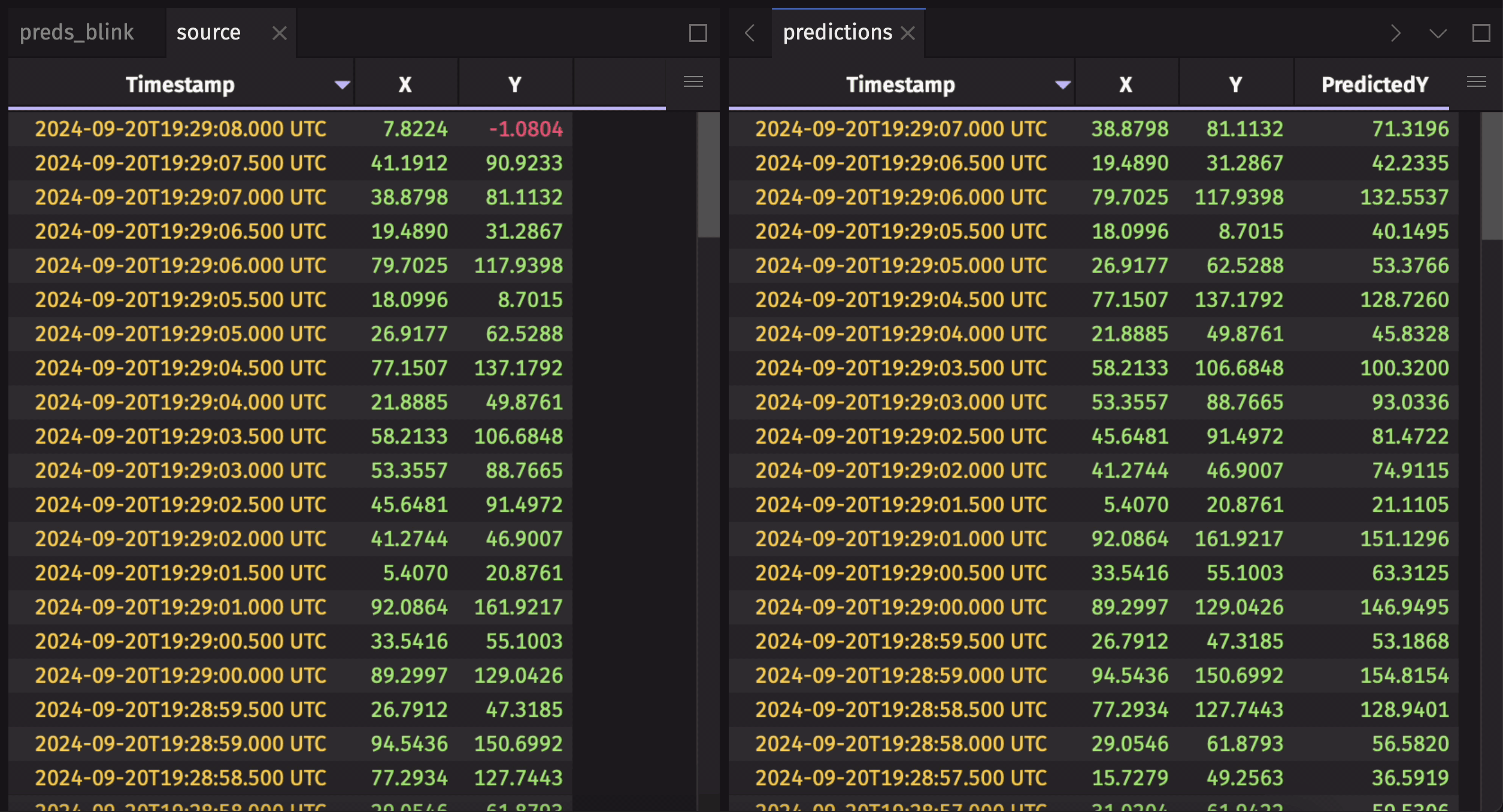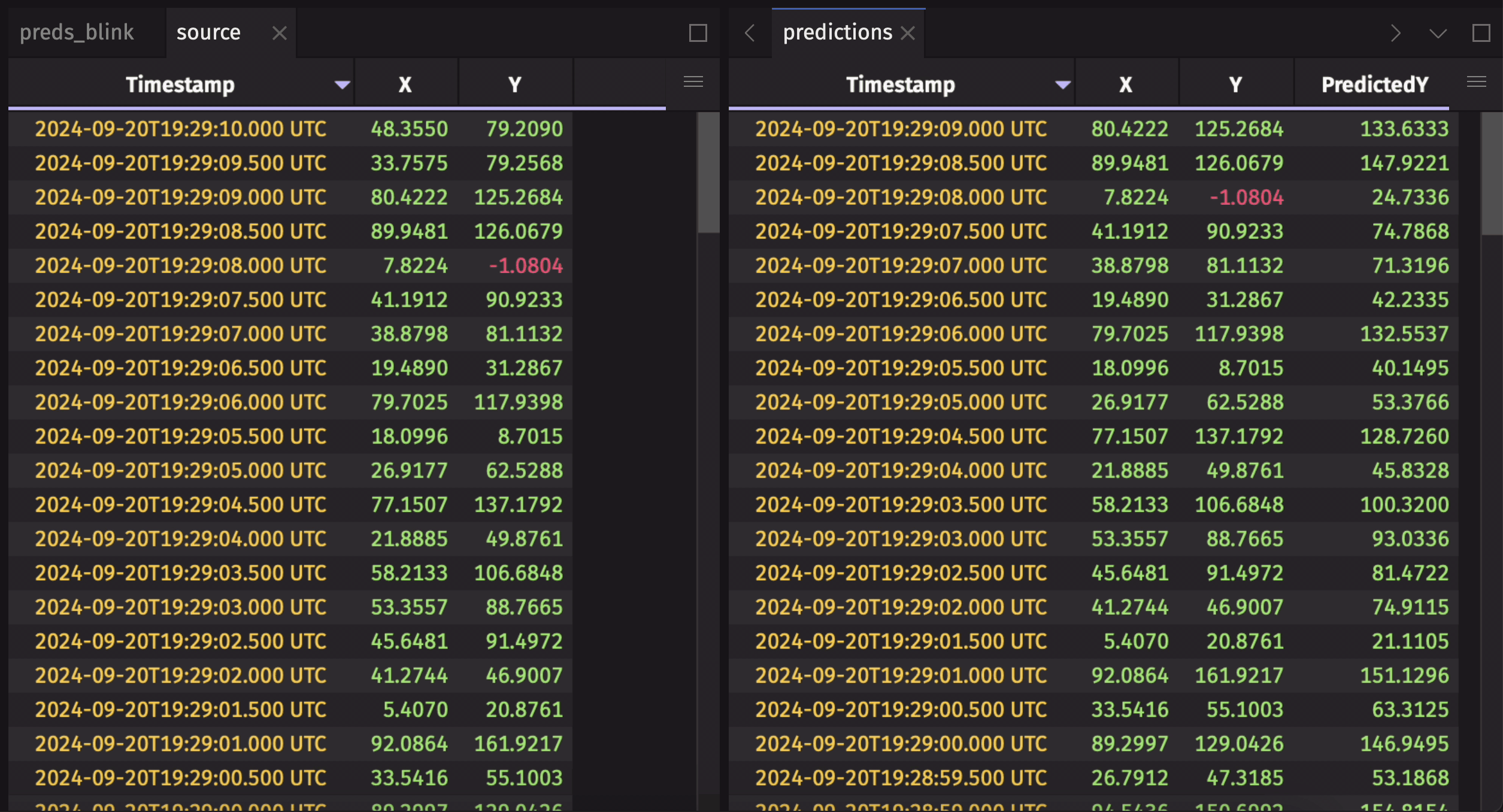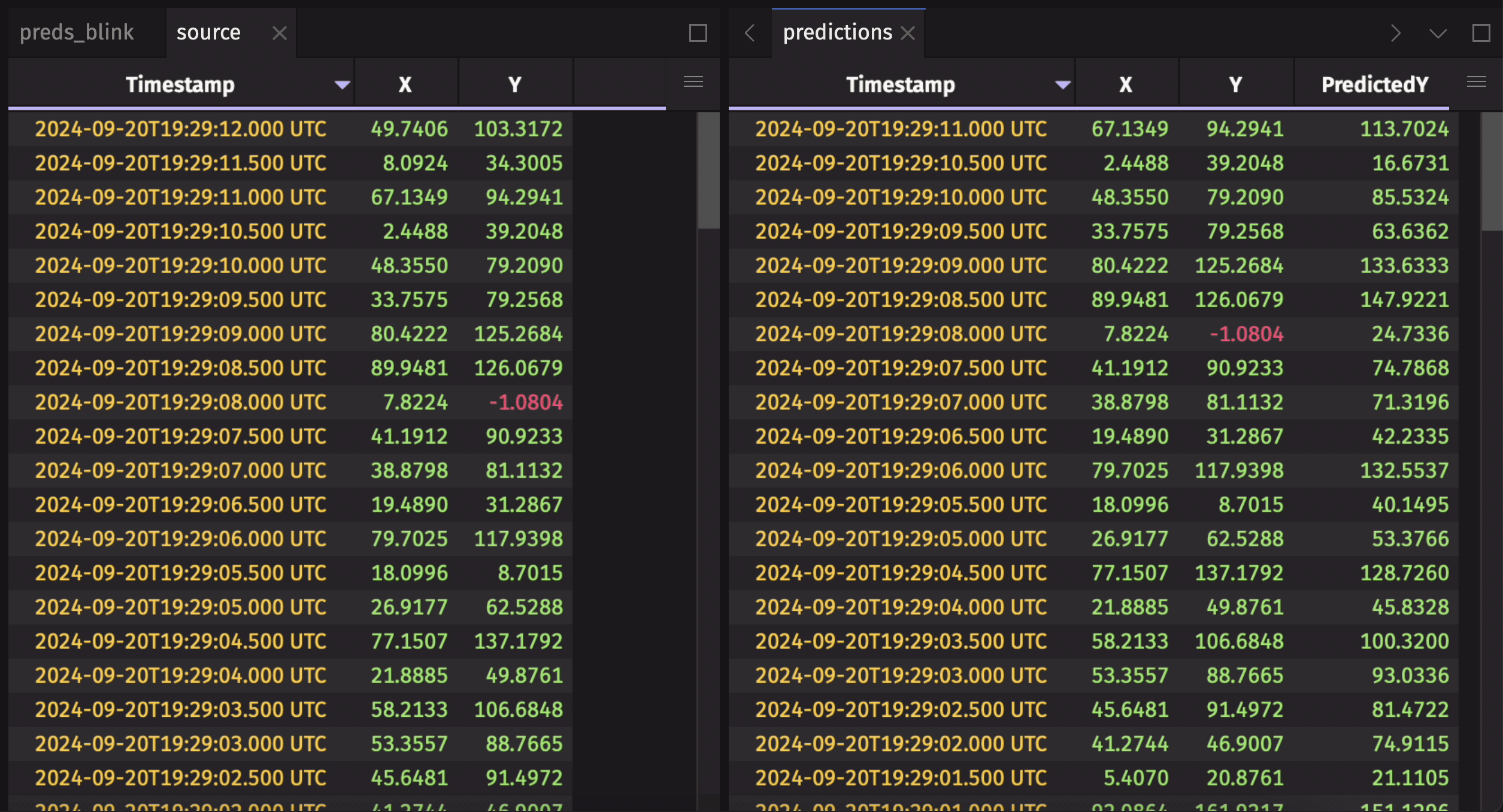
To learn more about this workflow, check out the AI/ML workflows user guide.
The deephaven.learn library
NOTE:
deephaven.learnonly works on append-only tables. See the previous section for another approach that works with all table types.
Aimed at ML/AI practitioners, deephaven.learn provides a general-purpose framework for efficient data interchange between Deephaven tables and Python objects such as NumPy arrays, Torch tensors, and more. deephaven.learn is fundamentally geared towards machine learning applications, as it enables models to be applied to real-time data.
deephaven.learn utilizes a gather-compute-scatter framework:
- Data is gathered from a table into a Python object.
- A computation is done on that object, possibly producing outputs.
- The results of the computation are scattered back into the table.
A simple and effective example of machine learning in Deephaven is Iris flower classification. It's an effective introductory problem in machine learning. The objective is to build a model that accurately predicts the class of Iris flower based on four measurements. This code will do so with a K-nearest neighbors model.
Gather
To gather table data into Python, use deephaven.learn.gather.table_to_numpy_2d. The following code block calls it in two functions: one for doubles, the other for ints. These will both be used shortly.
Compute
Machine learning applies models to data. Models typically produce no outputs when training, but do produce outputs when applied after training is complete. The following code block defines two functions. The first trains a K-nearest neighbors model on data, and the second applies the trained model. They will be used shortly.
Scatter
In this case, scattering Python data back into a table is simple. Since the model produces scalar outputs, a scatter function only needs to return the output at the correct index.
Put it all together
The deephaven.learn.learn function is the final piece of the puzzle. It takes the table, model function, and gather/scatter functions to both train the model as well as apply it to the table data.
First, train the model. Because this is a supervised learning model, two inputs are required: the features and the class labels. The training phase produces no outputs, so none are given.
With the trained model in hand, apply it to the table data. This time, an output is produced.
For more information, see the deephaven.learn guide.